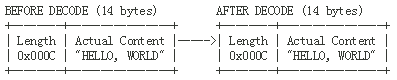Netty 解决 TCP 粘包或半包问题的策略
|
所谓 TCP 粘包就是接收端接收到的消息数据不能完整地体现发送端的消息数据。TCP 协议存在粘包的主要原因是 TCP 以“流”的方式来消息处理数据,而“流”是没有界限的一串消息数据。TCP 粘包通常在“流”传输中出现,而 UDP 协议有消息边界,UDP 不会出现粘包问题。 处理 TCP 粘包的唯一方法就是制定应用层的数据通讯协议,通过协议来规范现有接收的数据是否满足消息数据的需要。 为了解决网络数据流的拆包粘包问题,Netty 为我们内置了如下的解码器: ByteToMessageDecoder MessageToMessageDecoder LineBasedFrameDecoder StringDecoder DelimiterBasedFrameDecoder FixedLengthFrameDecoder ProtoBufVarint32FrameDecoder ProtobufDecoder LengthFieldBasedFrameDecoder Netty 还内置了如下的编码器: ProtobufEncoder MessageToByteEncoder MessageToMessageEncoder LengthFieldPrepender ByteToMessageDecoder 如果我们自己想要实现自己的半包解码器,我们可以继承 ByteToMessageDecoder,实现更加复杂的半包解码: public abstract class ByteToMessageDecoder extends ChannelInboundHandlerAdapter 我们只需要继承该类并实现 protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception; MessageToMessageDecoder MessageToMessageDecoder 一般作为二次解码器,当我们在 ByteToMessageDecoder 将一个 bytes 数组转换成一个 java 对象的时候,我们可能还需要将这个对象进行二次解码成其他对象,我们就可以继承这个类 public abstract class MessageToMessageDecoder<I> extends ChannelInboundHandlerAdapter 然后实现 protected abstract void decode(ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception; LineBasedFrameDecoder 通过在包尾添加回车换行符 \r\n 来区分整包消息。 LineBasedFrameDecoder 的原理是从 ByteBuf 的可读字节中找到 \n 或者 \r\n,找到之后就以此为结束,然后将当前读取到的数据组成一行。 如果我们设置每一行的最大长度,但是当达到最大长度之后还没有找到结束符,就会抛出异常,同时将读取的数据舍弃掉。 ch.pipline().addLast(new LineBasedFrameDecoder(1024)); DelimiterBasedFrameDecoder 通过特殊字符作为分隔符来区分整包消息。 使用 DelimiterBasedFrameDecoder 我们可以自定义设定分隔符 ByteBuf delimiter = Unpooled.copiedBuffer("$_".getBytes());
ch.pipline().addLast(new DelimiterBasedFrameDecoder(1024, delimiter));在上面的例子中我们使用了自定义的分隔符 $_,同样的如果在 1024 个字节中找不到 $_,也会抛出。 FixedLengthFrameDecoder 消息定长,报文大小固定长度,不够空格补全,发送和接收方遵循相同的约定,这样即使粘包了通过接收方编程实现获取定长报文也能区分。 FixedLengthFrameDecoder 为定长解码器,它会按照指定长度对消息进行解码。 ch.pipline().addLast(new FixedLengthFrameDecoder(1024)); 上面的例子会每隔1024个长度之后进行消息解码,如果不足 1024,则会将消息缓存起来,然后再进行解码。 ProtobufVarint32FrameDecoder 通过 Protobuf 解码器来区分整包消息。 Protobuf 全称为 Google Protocol Buffers,来自Google开源项目。 Protobuf 使用二进制编码,将数据结构以 .proto 文件进行描述,通过代码生成工具生成对应数据结构的 POJO 对象和 Protobuf 相关的方法和属性。
ProtoBufVarint32FrameDecoder 是 Netty 为我们提供的 Protobuf 半包解码器, 通过它配合使用 ProtobufDecoder 和 ProtobufEncoder 我们就可以使用 Protobuf 进行通信了。 ch.pipline().addLast(new ProtobufVarint32FrameDecoder()); ch.pipline().addLast(new ProtobufDecoder()); ch.pipline().addLast(new ProtobufEncoder()); LengthFieldBasedFrameDecoder 通过指定长度来标识整包消息,LengthFieldBasedFrameDecoder 是 Netty 为我们提供的通用半包解码器。 将消息分为消息头和消息体,消息头中包含表示信息的总长度(或者消息体长度)的字段。
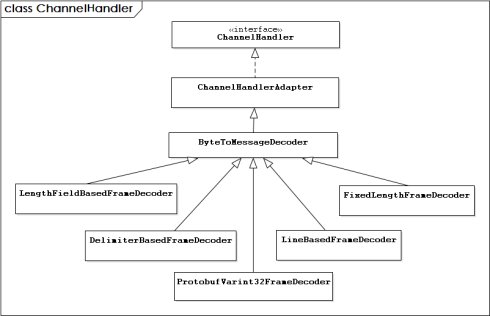
public class LengthFieldBasedFrameDecoder extends ByteToMessageDecoder MessageToByteEncoder 该类负责将 java 对象编码成 ByteBuf,我们只需要继承该类然后实现: protected abstract void encode(ChannelHandlerContext ctx, I msg, ByteBuf out) throws Exception; MessageToMessageEncoder 如果要将 java 对象不编码成 ByteBuf,而是编译成,其他对象,那我们可以继承这个类实现: protected abstract void encode(ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception; LengthFieldPrepender LengthFieldPrepender 是一个非常实用的工具类,如果我们在发送消息的时候采用的是:消息长度字段+原始消息的形式,那么我们就可以使用 LengthFieldPrepender 了。这是因为 LengthFieldPrepender 可以将待发送消息的长度(二进制字节长度)写到 ByteBuf 的前俩个字节。 例如: Hello,World 编码前是12个字节,但是经过 LengthFieldPrepender 编码后变成了: 0x000E Hello,World 在 Netty 框架中常用解码器类层次图(部分):
转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |