Getting Started with ElasticSearch
|
Introduction ElasticSearch is an open-source and distributed search engine which is very much scalable and supports a good amount of enterprise Search use cases. It's built on top of Lucene (just like Apache Solr4). It supports realtime time indexing and full text search. You can read about Elastic Search at: It exposes a Java and an HTTP API, which can be used for indexing, searching and most of the configuration. The very reason for writing this blog about ElasticSearch is that http://www.elasticsearch.org/ is more of a reference type and there are no good quality and complete tutorials available. I had some struggle in terms of making it up and running beyond a basic hello world program. I am sharing my experiences so that it can save some time for audiences who would like to try out ElasticSearch (which is a very powerful suite of product). At the end of this tutorial - you will be having a very basic Elastic Search tutorial - up and running. I will be sharing the link from my PC. So let's get started. 1. I am assuming that you have Java already installed. 2. Download ElasticSearch from http://www.elasticsearch.org/download/. Again, there is a lot of talk about using it in Linux and other non-windows environment, but I will be focusing more into Windows 7 Desktop environment. Please choose the installation package accordingly. For Windows - it's a Zip file - one can extract it into C:\elasticsearch-0.90.3\. Remember it's very much like installing Eclipse IDE. 3. I am new to Curl and cygwin and i wanted to cut short the time frame to learn it (as most of the command references on ElasticSearch.org are for non-Windows platform). You can install Curl from http://curl.haxx.se/download.html and cygwin from http://cygwin.com/install.html Now let's test what we have done till now. 1. In Windows7 Desktop Environment, start command line and cd C:\elasticsearch-0.90.3\bin 2. Now execute elasticsearch.bat 3. This will start one of the ElasticSearch nodes on the localhost. You will see the logs somewhat like this (Please don't worry if it is slightly different in your case, as I have some plugins of Elastic Search and my node names etc... are going to be different from yours)
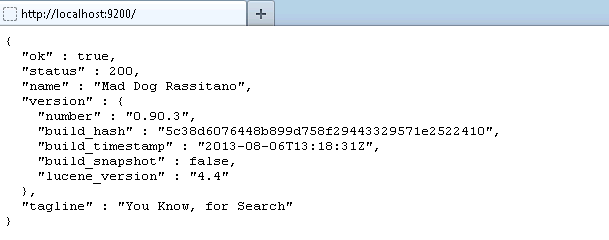
4. Now test it in your browser
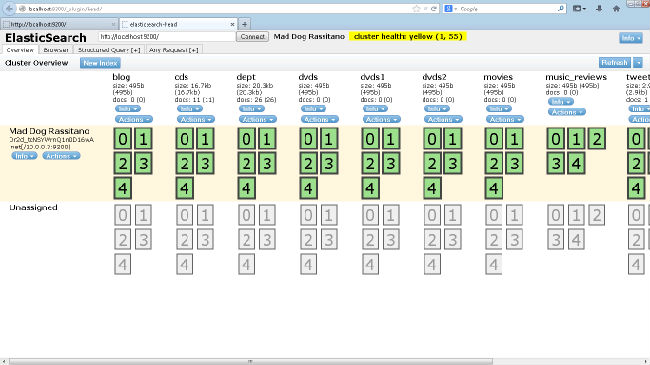
If you get status 200 it means - everything is fine... Isn't it simple? Let's look at each field of the JSON and see what it's about: Ok: when it's true, it means that the request was successful. Status: the HTTP error code that resulted from the request. 200 means OK. Name: the name of our Elasticsearch instance. By default, it picks a random name from a huge list of names. Version: The object here has a number field, which is the version of Elasticsearch you're currently running, and a snapshot_build field, which indicates if what you're running has been built from sources. Tagline: this contains the first tagline of Elasticsearch: "You Know, for Search." 5. Now let's install one of the elasticsearch plugin viz. ElasticSearch Head from http://mobz.github.io/elasticsearch-head/ It's very simple to install this plug-in. cd C:\elasticsearch-0.90.3\bin plugin -install mobz/elasticsearch-head This will install elasticsearch-head plugin into your environment Let's test it out Please type this into the browser: http://localhost:9200/_plugin/head/ It should look something like this:
This is the overview which talks about cluster health and various indexes. Now you can play with this plugin and may be work on your search projects. Hope this can get you started on a very good Opensource Enterprise Search Product viz. "ElasticSearch". Reference http://java.dzone.com/articles/elasticsearch-getting-started 转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |