|
Cache 一致性问题 单核 Cache 中每个 Cache line 有2个标志:dirty 和 valid 标志,它们很好的描述了 Cache 和 Memory 之间的数据关系(数据是否有效,数据是否被修改),而在多核处理器中,多个核会共享一些数据。
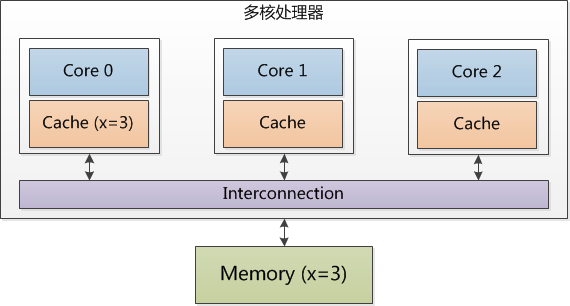
只有 Core 0 访问变量 x,它的 Cache line 数据和内存中的数据一致,数据只存在于本 Cache 中。
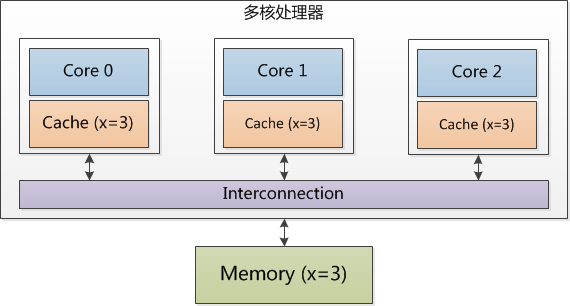
3个 Core 都访问变量 x,它们对应的 Cache line 数据和内存中的数据一致,数据存在于很多 Cache 中。
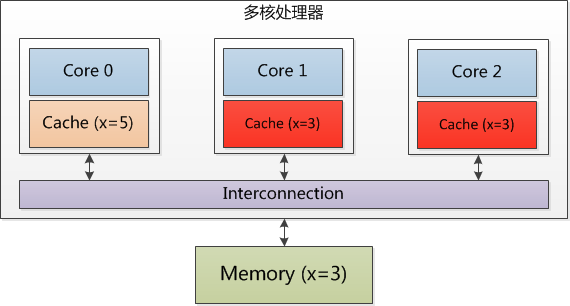
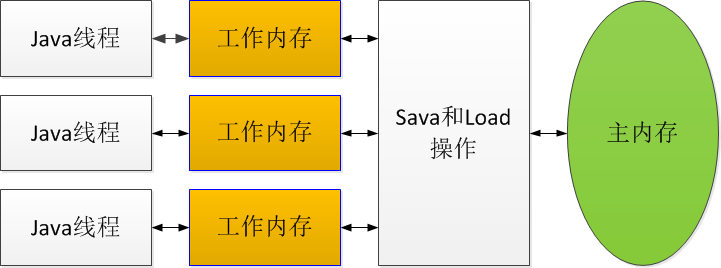
Core 0 修改了x的值之后,这个 Cache line 数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中。其他 Core 对应的 Cache line 数据无效。 内存栅栏 简单来说,内存栅栏(Memory Barrier)就是从本地或工作内存到主存之间的拷贝动作。
仅当写操作线程先跨越内存栅栏而读线程后跨越内存栅栏的情况下,写操作线程所做的变更才对其他线程可见。关键字 synchronized 和 volatile 都强制规定了所有的变更必须全局可见,该特性有助于跨越内存边界动作的发生,无论是有意为之还是无心插柳。 在程序运行过程中,所有的变更会先在寄存器或本地 cache 中完成,然后才会被拷贝到主存以跨越内存栅栏。此种跨越序列或顺序称为 happens-before。 写操作必须要 happens-before 读操作,即写线程需要在所有读线程跨越内存栅栏之前完成自己的跨越动作,其所做的变更才能对其他线程可见。 内存对齐 为何要内存对齐? 1. 平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的,某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。 2. 性能原因:经过内存对齐后,CPU的内存访问速度大大提升。
这是普通程序员心目中的内存印象,由一个个的字节组成,而 CPU 并不是这么看待的。
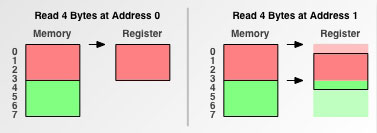
CPU 把内存当成是一块一块的,块的大小可以是2,4,8,16字节大小,因此 CPU 在读取内存时是一块一块进行读取的。块大小成为 memory accessgranularity(粒度)本人把它翻译为"内存读取粒度"。 假设CPU要读取一个int型4字节大小的数据到寄存器中,分两种情况讨论: 1. 数据从0字节开始 2. 数据从1字节开始 再次假设内存读取粒度为4。
当该数据是从0字节开始时,CPU 只需读取内存一次即可把这4字节的数据完全读取到寄存器中。 当该数据是从1字节开始时,问题变的有些复杂,此时该 int 型数据不是位于内存读取边界上,这就是一类内存未对齐的数据。
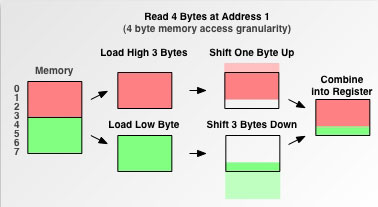
此时 CPU 先访问一次内存,读取0—3字节的数据进寄存器,并再次读取4—5字节的数据进寄存器,接着把0字节和6,7,8字节的数据剔除,最后合并1,2,3,4字节的数据进寄存器。对一个内存未对齐的数据进行了这么多额外的操作,大大降低了 CPU 性能。 这还属于乐观情况了,上文提到内存对齐的作用之一为平台的移植原因,因为以上操作只有有部分 CPU 肯干,其他一部分 CPU 遇到未对齐边界就直接罢工了。 转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |