聊聊事务
|
前言 关于事务(transaction),相信对于每一个从事软件开发行业的人来说,它都不是一个陌生的词汇,在日常的开发工作中几乎每天都会接触到(遥想公瑾当年面试的时候还被问道了相关的问题),下面我们就来聊聊事务。 概念 对于事务的概念,网上有各种版本,大同小异,事务就是是由一系列对系统中数据进行读写的操作组成的一个程序执行单元,狭义上的事务特指数据库事务。 特性 事务有那些特性呢?
以上就是事务的四个特性了,也就是我们常说的ACID。 事务隔离级别 上文中我们说到了事务的隔离性,如果不考虑事务隔离会有什么问题呢?我们来看几个简单的事例:
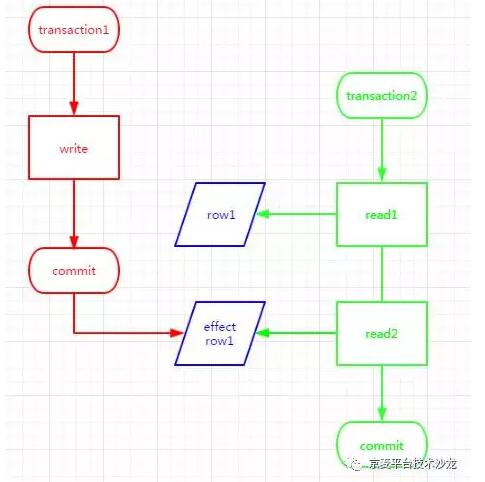
如上图所示,事务2读取了事务1改写但还未提交的数据,如果这些数据被事务1回滚了,则事务2读到的数据是无效的,这时就发生了脏读。
如上图所示,事务2在两次读取row1的过程之间,row1被事务1改写了,从而导致事务2两次读取同一数据返回的结果是不一样的,这时就发生了不可重复读。
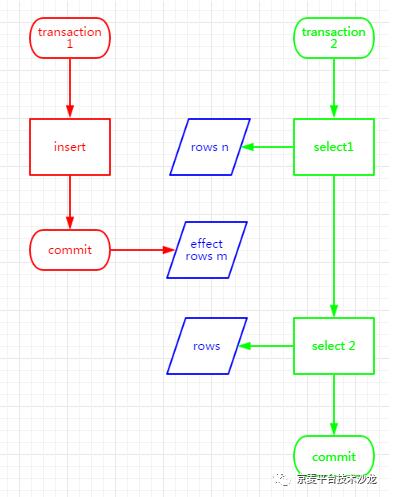
如上图所示,事务2在读取了n行记录后,事务1插入了m行记录,事务2以同样的查询条件再次读取,结果却变成了m+n行记录,事务2的第二次读取发现了一些在第一次读取中没有的记录,这时就发生了幻读。 ISO/ANSISQL92规范中定义了四种事务隔离级别来解决上述问题:
以上四个隔离级别的隔离性依次增强,事务隔离级别越高,就越能保证数据的完整性和一致性,但同时对并发性能的影响也越大,对于绝大多数应用来说,可以优先考虑将数据库的隔离级别设置为READ_COMMITE,这能够在避免脏读的同时保证较好的并发性能,尽管这种事务隔离级别会导致不可重复读和幻读等并发问题,但较为科学的做法是在可能出现这类问题的个别场合中,由应用程序主动采用悲观锁或乐观锁来进行事务控制。 应用 我们以MySQL中最常用的数据存储引擎Innodb为例,来介绍一下事务的应用,在进入应用之前,简单的介绍一下MySQL的锁机制,MySQL有三种锁机制,行锁、表锁和页锁,前两种不用多说,字面理解即可。行锁不是MySQL自己实现的锁定方式,而是由其他存储引擎自己所实现的,如广为大家所知的Innodb存储引擎,以及MySQL的分布式存储引擎NDBCluster等都是实现了行级锁定,Innodb的锁定模式实际上可以分为四种:共享锁(S)、排他锁(X)、意向共享锁(IS)和意向排他锁(IX)。表锁分为读锁和写锁。页级锁定比较特殊,在其他的数据库软件中也不是很常见,MySQL的BerkeleyDB存储引擎使用了页级锁定。数据库锁机制不是本文的主要内容,有兴趣的可以自行查阅资料,网上相关的资料满大街都是。 Innodb的事务管理和锁定机制中,有专门检测死锁的机制,会在系统中产生死锁之后的很短时间内就检测到该死锁的存在。当Innodb检测到系统中产生了死锁之后,Innodb会通过相应的判断来选这产生死锁的两个事务中较小的事务来回滚,而让另外一个较大的事务成功完成。那Innodb是以什么来为标准判定事务的大小的呢?MySQL官方手册中也提到了这个问题,实际上在Innodb发现死锁之后,会计算出两个事务各自插入、更新或者删除的数据量来判定两个事务的大小。也就是说哪个事务所改变的记录条数越多,在死锁中就越不会被回滚掉。但是有一点需要注意的就是,当产生死锁的场景中涉及到不止Innodb存储引擎的时候,Innodb是没办法检测到该死锁的,这时候就只能通过锁定超时限制来解决该死锁了。 Innodb事务锁定机制示例 准备工作: mysql> create table test (a int(11),b varchar(16)) engine=innodb; Query OK, 0 rows affected (0.02 sec) mysql> create index idx_a on test(a); Query OK, 0 rows affected (0.05 sec) Records: 0 Duplicates: 0 Warnings: 0 mysql> create index idx_b on test(b); Query OK, 11 rows affected (0.01 sec) Records: 11 Duplicates: 0 Warnings: 0
合理使用索引和控制事务粒度可以避免数据库发生长时间的阻塞甚至死锁,在高并发环境中,应当尽量避免大量的关联查询和子查询等会发生大面积锁的操作,事务的粒度不要过大,必要时可以拆解事务并采用一些补偿机制,一些对实时性要求不高的写操作可以异步化,也可以使用搜索引擎和NOSQL来缓解数据库的压力。 在那个大名鼎鼎的叫春(spring)的框架中,对事务操作有很好的支持,不仅有对事务隔离级别的支持,还定义了6种事务传播行为来支持事务的嵌套、挂起、与非事务的转化等等一系列操作。spring提供了声明、注解、aop切面三种方法我供我们使用spring事务,其中声明式事务因为对代码入侵较大并且编码工作较多所以不被推荐使用,注解和aop切面的方式可以基于需求自行选择,具体的使用方法在这里不做赘述,出门往哪边转都能找到。 分布式事务 目前,绝大多数的电商系统都由于集中式系统单点故障、大型计算机昂贵和扩容艰难等致命问题从而转换为分布式,分布式系统虽然可以解决上述问题,但它更为复杂,同时也带来了很多新的问题,其中一个就是分布式事务处理,在单机数据库中,我们很容易就能够实现一套满足ACID特性的事务处理系统,但在分布式数据库中,数据分散在不同的机器上,如果对这些数据进行分布式的事务处理具有非常大的挑战。 针对分布式事务,加州大学的一个教授提出了著名的CAP理论,一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个基本需求,最多只能同时满足其中两项。既然是分布式系统,保证分区容错性是最基本的要求,我们需要根据业务特点在一致性和可用性之间寻求平衡。ebay的架构师根据CAP理论在一致性和可用性之间做出权衡之后,提出了BASE理论,BASE是由基本可用(Basically Available)、软状态(Soft state)和最终一致性(Eventually consistent)三个短语组成。基本可用就是当机器发生故障的时候可以允许响应时间上的损失,大促高峰的时候,部分用户可能会被降级。软状态允许不同节点的数据副本之间进行数据同步时存在延迟。最终一致性即为系统数据最终能够达到一致的状态,不需要实时保证。在解决分布式数据一致性的过程中,涌现了一大批经典的一致性协议和算法,例如2PC、3PC、Paxos、ZAB(Zookeeper的一致性协议)等,基于这些协议,产生诸如Chubby、Zookeeper等优秀的解决分布式一致性问题的服务,推荐有兴趣的读者参考《从PAXOS到ZOOKEEPER分布式一致性原理与实践》这本书来学习分布式事务和数据一致性解决方案相关内容,关于分布式事务,笔者也在不断的研习中,希望志同道合之士能够不吝赐教,笔者不胜感激。 转载请并标注: “本文转载自 linkedkeeper.com (文/张强)” ©著作权归作者所有 |