Model Operating Systems - Processes And Threads
|
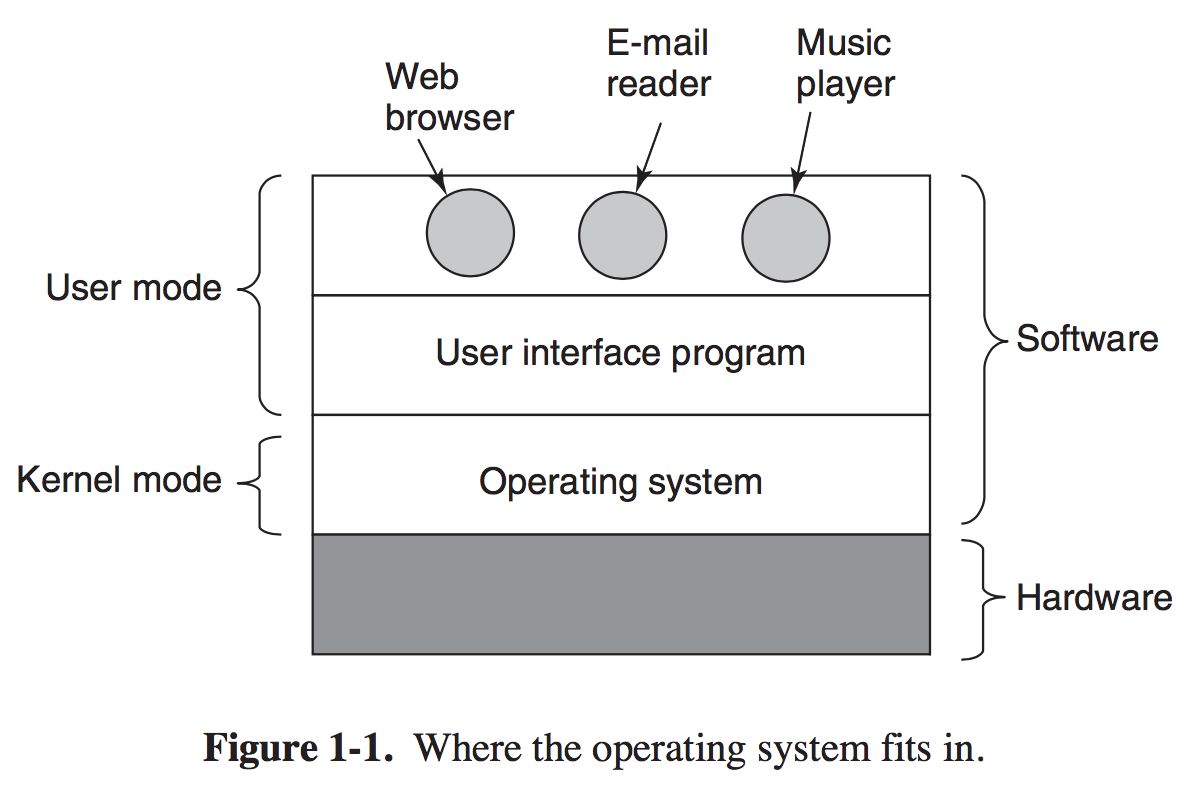
Why do most computers have two modes of operation? (Kernel Mode and User Mode) Kernel mode has complete access to all the hardware and can execute any instruction the machine is capable of executing. The rest of the software runs in user mode, in which only a subset of the machine instructions is available.
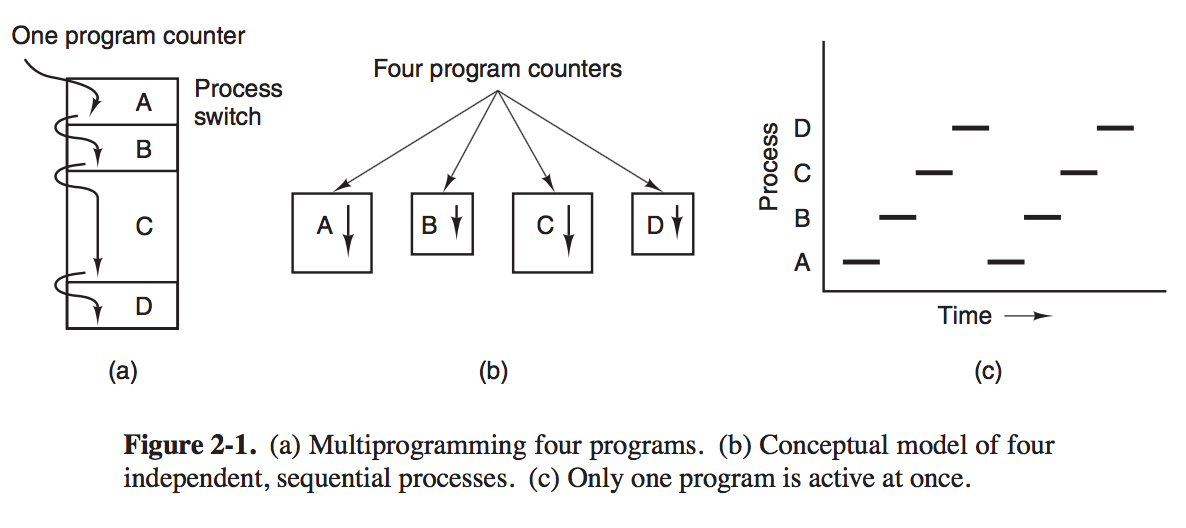
Operating System providing application programmers a clean abstract set of resources instead of messy hardware ones and managing these hardware resources. The abstraction is the key to managing all this complexity. Operating System Concepts - Processes And Threads Processes Process is an abstraction of a running program. Processes support the ability to have concurrent operation even when there is only on CPU available. Threy turn a single CPU into multiple virtual CPUs. # The Process Model In this model, all the runnable software on the computer, sometimes including the operating system, is organized into a number of sequential processes, or just processes for short. A process is just an instance of an executing program, including the current values of the program counter, registers, and variables. In Fig. 2-1 we see a computer multiprogramming four programs in memory.
# Process Creation Four principal events cause processes to be created: 1. System initialization. 2. Execution of a process-creation system call by a running process. 3. A user request to create a new process. 4. Initiation of a batch job. In both UNIX and Windows systems, after a process is created, the parent and child have their own distinct address spaces. In UNIX, the child's initial address space is a copy of the parent's, but there are difinitely two distinct address spaces involved; no writable memory is shared. In Windows, the parent's and child's address spaces are different from the start. # Process Termination Most processes terminate because they have done their work. When a compiler has compiled the program given to it, the compiler executes a system call to tell the operating system that it is finished. The second reason for termination is that the process discovers a fatal error. The third rease for termination is an error caused by the process, othen due to a program bug. The fourth reason a process might terminate is that the process executes a system call telling the operating system to kill some other process. # Process States Four transitions are possible among these states, as shown.
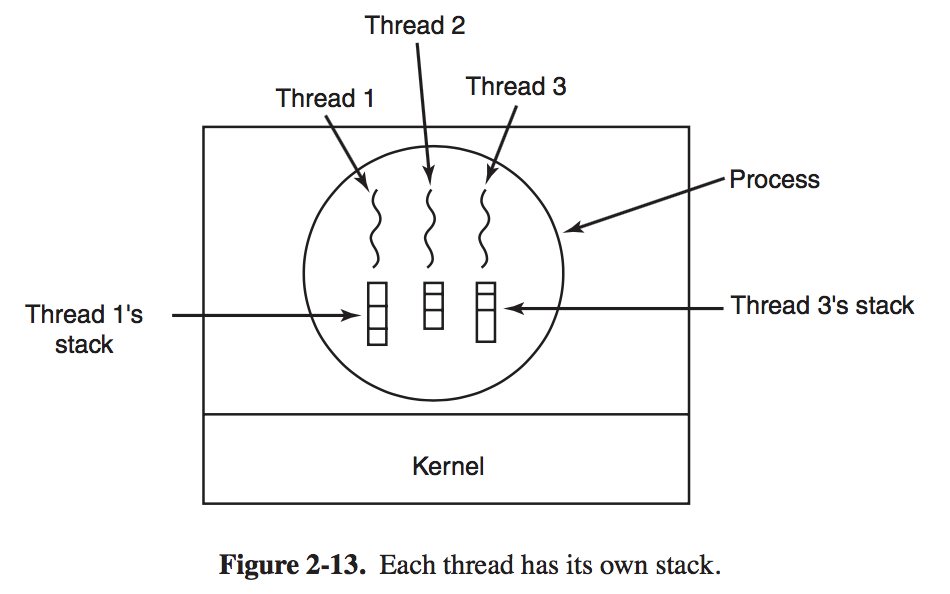
Threads # Thread Usage The main reason for having threads is that in many applications, multiple activities are going on at once. Only now with threads we add a new element: the ability for the parallel entities to share an address space and all of itsdata among themselves. The ability is essential for centain applications, which is why having multiple processes ( with their separate address spaces) will not work. # The Classical Thread Model A process has an address space containing program text and data, as well as other resources. In Fig. 2-11(a) we see three traditional processes. Each process has its own address space and a single thread of control. In contrast, in Fig. 2-11(b) we see a single process with three threads of control. Although in both cases we have three threads, in Fig. 2-11(a) each of them operates in a different address spaces, whereas in Fig. 2-11(b) all three of them share the same address spaces.
It is important to realize that each thread has its own stack. Each thread's stack contains one frame for each procedure called but not yet returned from. This frame contains the procedure's local variables and the return address to use when the procedure call finished.
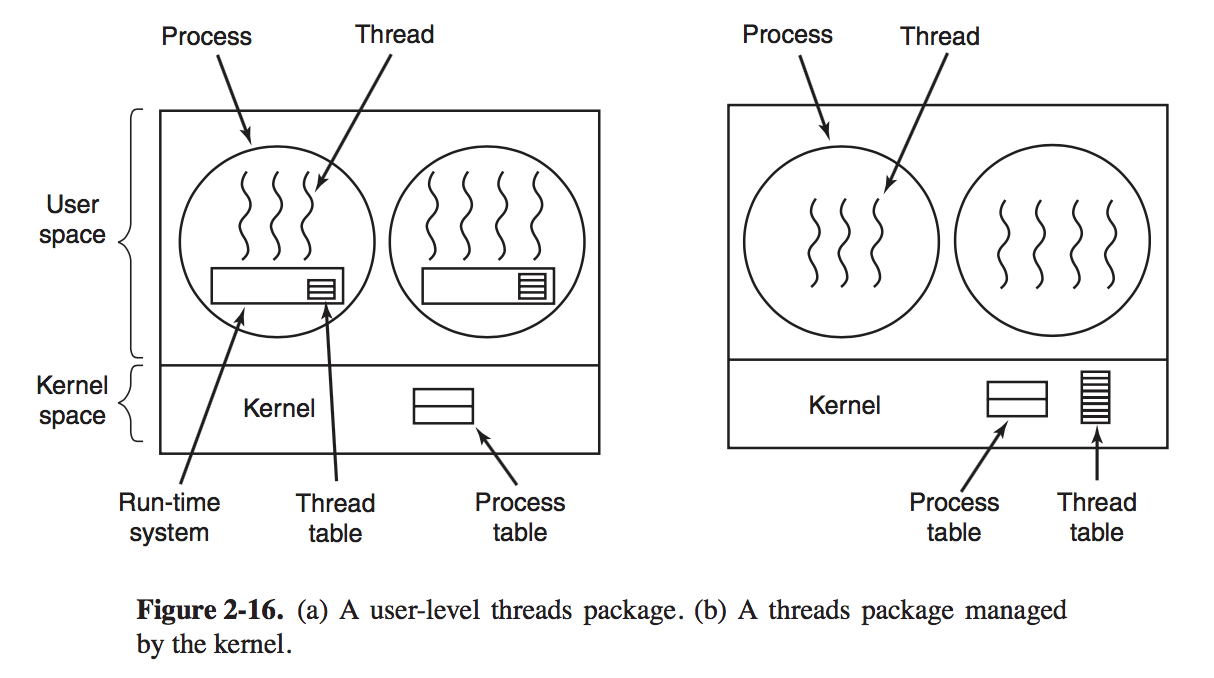
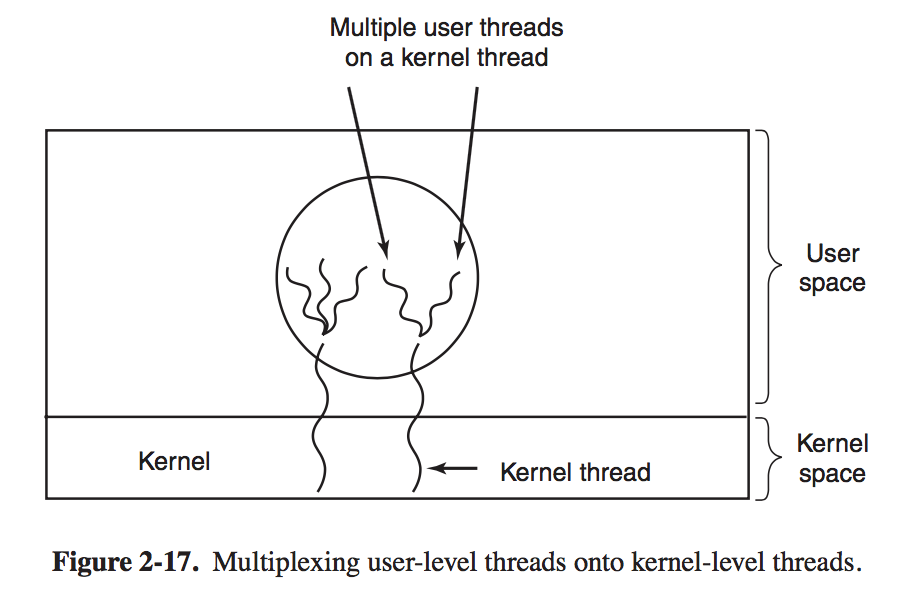
# Implementing Threads in User Space and Kernel Space There are two main places to implement threads: user space and the kernel.
When threads are managed in user space, each process needs its own private thread table to keep track of the trheads in that process. Instead, the kernel has a table that keeps track of all the threads in the system. When a thread wants to create a new thread or destroy an existing thread, it makes a kernel call, which then does the creation or desturction by updating the kernel thread table. # Hybrid Implementations With this approach, the kernel is aware of only the kernel-level threads and schedules those. Some of those threads may have multiple user-level threads multiplexed on top of them.
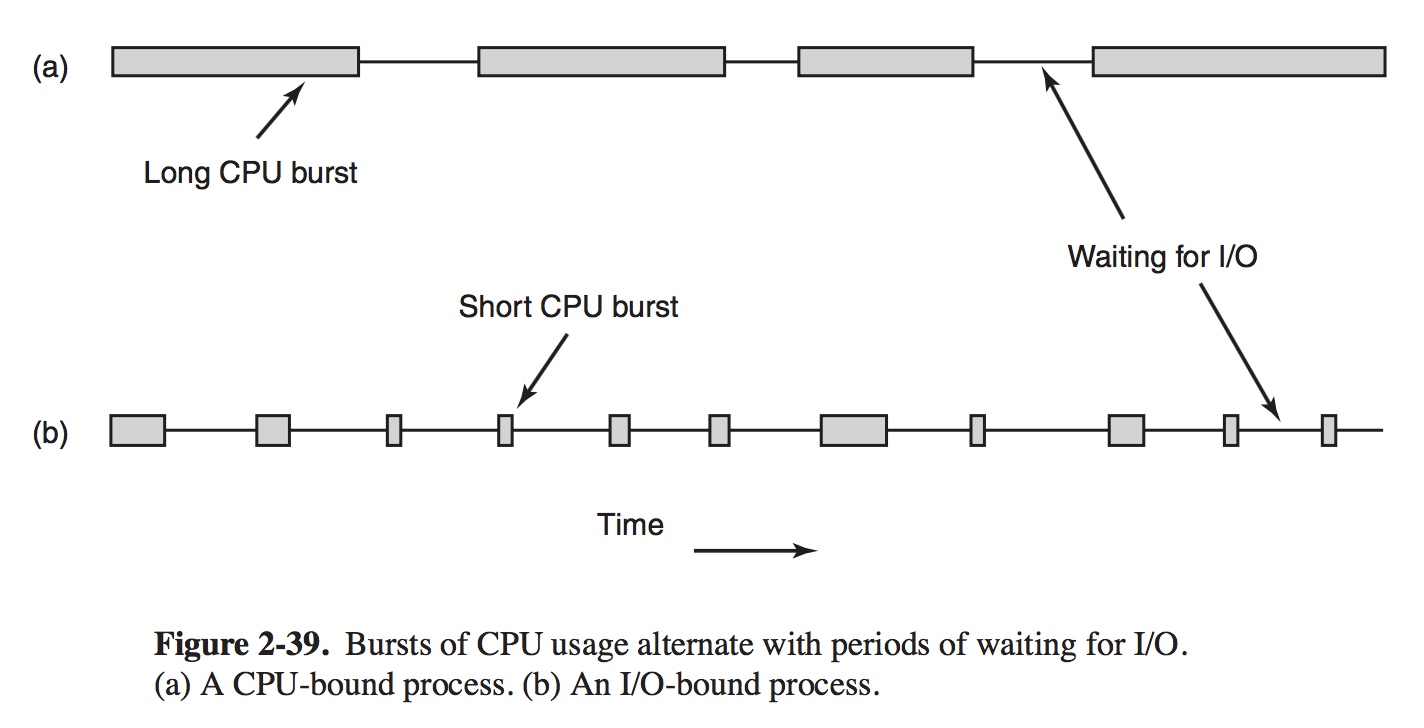
In this model, each kernel-level thread has some set of user-level threads that take turns using it. Scheduling When a computer is multiprogrammed, it frequently has multiple processes or threads competing for the CPU at the same time. This situation occurs whenever two or more of them are simultaneously in the ready state. When the kenrel manages threads, scheduleing is usually done per thread, with little or no regard to which process the thread belongs. # Process Behavior Nearly all Processes alternate bursts of computing with I/O requests. Often, the CPU runs for a while without stopping, then a system call is made to read from a file or wirte to a file. When the system call completes, the CPU computes again until it needs more data or has to write more data, and so on. For example, when the CPU copies bits to a video RAM to update screen, it is computing, not doing I/O, because the CPU is in use. I/O in this sense is when a process enters the blocked state waiting for an external device to complete its work.
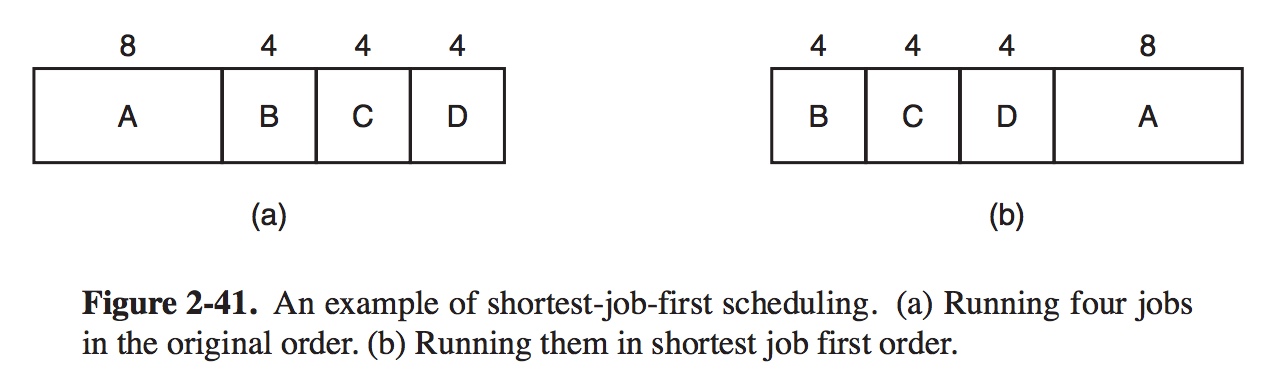
# When to Schedule It turns out that there are a variety of situations in which scheduling is needed. First, when a new process is created, a decision needs to be made whether to run the parent process or the child process. Second, a scheduling decision must be made when a process exits. Third, when a process blocks on I/O, on a semaphore, or for some other reason, anthoer process has to selected to run. Fourth, when an I/O interrupt occurs, a scheduling decision my be made. # Scheduling Algorithms In differnet envirenments different scheduling algorithms are needed. Thres environments worth distinguishing are: (1) Batch. (2) Interactive. (3) Real time. In batch system, there are no users impatiently waiting at their terminals for a quick response to a short request. This approach reduces process switches and thus improves performance. In an environment with interactive users, preemptive is essential to keep one process from hogging the CPU and denying service to the others. In system with read-time constraints, preemption sometimes is not need. The difference with interactive systems is that real-time systems run only programs that are intended to further the application at hand. # Scheduling in Batch Systems # First-Come, First-Served Basically, there is a single queue of ready processes. When the first job enters the system from the outside in the morning, it is started immediately and allowed to run as long as it wants to. As other jobs come in, they are put onto the end of the queue. When the running process blocks, the first process on the queue is run next. When a blocked process becomes ready, like a newly arrived job, it is put on the end of the queue, behind all waiting processes. # Shortest Job First When several equally important jobs are sitting in the input queue waiting to be started, the scheduler picks the shortest job first.
# Shortest Remainning Time Next With this algorithm, the scheduler always choose the process whose remaining run time is the shortest. Again here, the run time has to be known in advance. When a new job arrives, its total time is compared to the current process' remaining time. # Scheduling in Interactive Systems # Round-Robin Scheduling One of the oldest, simplest, fairest, and most widely used algorithms is round robin. Each process is assigned a time interval, called its quantum, during which it is allowed to run. If the process is still running at the end of the quantum, the CPU is preempted and given to another process. If the process has blocked or fin- ished before the quantum has elapsed, the CPU switching is done when the process blocks, of course. All the scheduler needs to do is maintain a list of runnable processes. When the proc- ess uses up its quantum, it is put on the end of the list. Switching from one process to another requires a certain amount of time for doing all the administration — saving and loading registers and memory maps, updating various tables and lists, flushing and reloading the memory cache, and so on. Setting the quantum too short causes too mana proccess switches and lowers the CPU efficiency, but setting it too long may cause poor response to short interactive request. A quantum around 20-50 msec is often a reasonable compromise.
# Priority Scheduling Round-robin scheduling makes the implicit assumption that all processes are equally important. The basic idea of priority scheduling is straighforward: each process is assigned a priority, and the runnable process with the highest priority is allowed to run. To prevent high-priority processess from running indefinitely, the scheduler may decrease the priority of the currently running process at each clock tick. If this action causes its priority to drop below that of the next highest process, a process switch occurs. Priorities can be assigned to processes statically or dynamically. # Multiple Queues Processes in the highest class were run for one quantum. Processes in the next-highest class were run for two quanta. Processess in the next one were run for four quanta, etc. Whenever a process used up all the quanta allocated to it, it was moved down one class. # Thread Scheduling
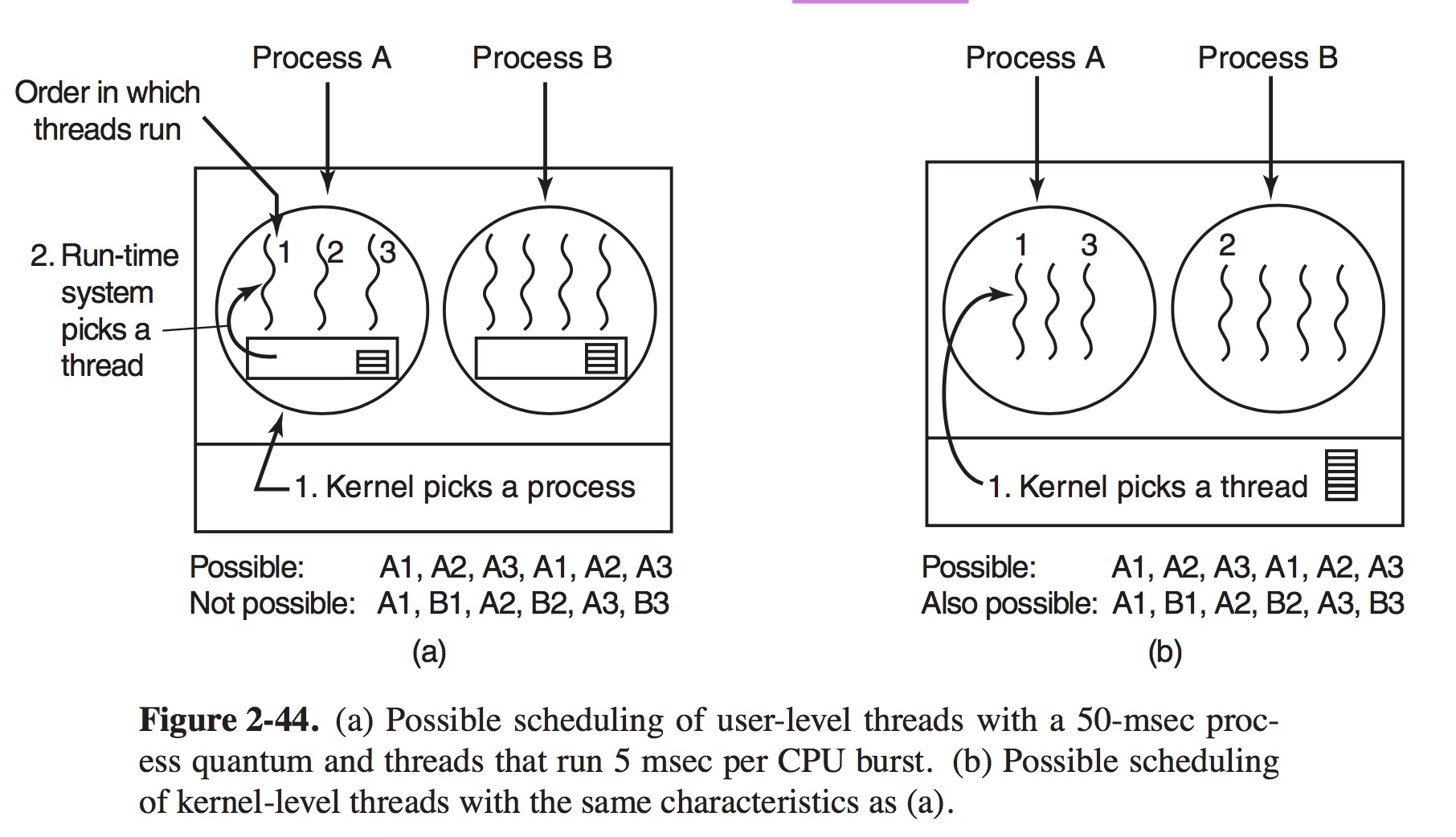
The scheduling algorithm used by the run-time system can be any of the ones described above. A major difference between user-level threads and kernel-level threads is the performance. Doing a thread switch with user-level threads takes a handful of machine instructions. With kernel-level threads it requires a full context switch, changing the memory map and invalidating the cache, which is several orders of magnitude slower. Another important factor is that user-level threads can employ an application-specific thread scheduler. This strategy maximizes the amount of parallelism in an environment where workers frequently block on disk I/O. PROBLEMS: Can a thread ever be preempted by a clock interrupt? If so, under what circumstances? If not, why not? What is the biggest advantage of implementing threads in user space? What is the biggest disadvantage? In a system with threads, is there one stack per thread or one stack per process when user-level threads are used? What about when kernel-level threads are used? Explain. 转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |