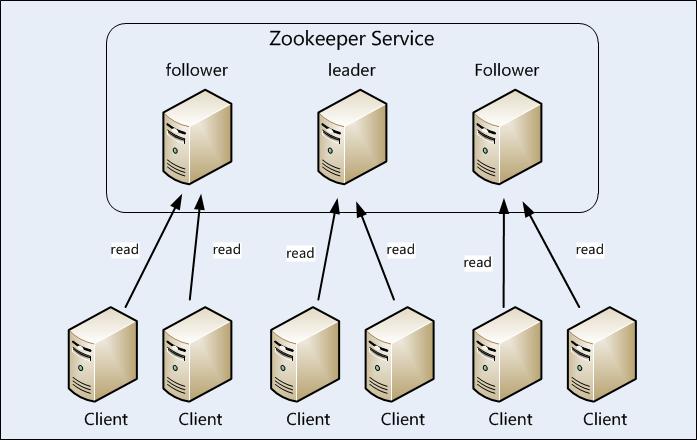
Zookeeper服务
|
数据模型 Zookeeper维护着一个树形层次结构,树中的节点称为znode。znode可以用于存储数据,并且有一个与之相关联的ACL。Zookeeper被设计用来实现协调服务,通常是小数据文件,而不是用于大数据容器存储,因此一个znode能存储的数据被限制在1MB以内。 Zookeeper的数据访问具有原子性。客户端在读取一个znode的数据时,要么读取到所有数据,要么读操作失败,不会只读到部分数据。同样,写操作将替换znode存储额所有数据。Zookeeper会保证写操作不成功就失败,不会出现部分写之类的情况,也就是不会出现只保存客户端所写部分数据的情况。Zookeeper不支持添加操作。这些特性和HDFS不同,HDFS被设计用于大数据存储,支持流式数据访问和添加操作。 znode通过路径被引用。像Unix中文件操作路径一样,在Zookeeper中路径被表示成用斜杠分隔的Unicode字符串。与Unix中的文件系统路径不同,Zookeeper中路径必须是绝对路径,也就是说每条路径必须从一个斜杠字符开始。 短暂znode znode有两种类型:短暂和持久的。znode的类型在创建时确定并且之后不能再修改。在创建短暂znode的客户端回话结束时,Zookeeper会将该短暂znode删除。相比之下,持久znode不依赖于客户端会话,只有当客户端明确要删除该持久znode时才会被删除,短暂znode不可以有子节点,即使是短暂子节点。 观察 znode以某种方式发生变化时,"观察"(watch)机制可以让客户端得到通知。可以针对ZooKeepr服务的操作来设置观察,该服务的其他操作可以触发观察。 观察只触发一次。为了能够多次收到通知,客户端需要重新注册所需的观察。 操作 Zookeeper服务的操作 create:创建一个znode(必须要有父节点) 观察触发器 在读操作exist、getChildren和getData上可以设置观察,这些观察可以被写操作create、delete和setData出发。ACL相关的操作不参与任何观察。当一个观察被触发时会产生一个观察事件,这个观察和触发它的操作共同决定了观察时间的类型。 当所观察的znode被创建、删除或其数据被更新时,设置在exists操作上的观察将被触发。 当所观察的znode被删除或其数据被更新时,设置在getData操作上的观察将被触发。创建znode不会出发getData操作上的观察,因为getData操作成功执行的前提是znode必须已经存在。 当所观察的znode的一个子节点被创建或删除时,或所观察的znode自己被删除时,设置在getChildren操作上的观察将会被触发。你可以通过观察事件的类型来判断被删除的是znode还是其子节点:NodeDelete代表znode被删除;NodeCHildrenChanged代表一个子节点被删除。 ACL ACL权限: CREATE:create(子节点) 注意exists操作不受ACL权限的限制,因此任何客户端都可以调用exists来检查一个znode的状态或查询一个znode是否存在。 在类ZooDefs.Ids中有一些预定义的ACL,OPEN_ACL_UNSAFE是其中一只,它将所有的权限(不包括ADMIN)授予每个人。 实现 从概念上来说,Zookeeper是非常简单的:它所做的就是确保对znode数的每一个修改都会被复制到集合体中超过半数的机器上。如果少于半数的机器出现故障,则最少有一台机器会保存最新的状态。其余的副本最终也会更新到这个状态。 然而,这个简单想法的实现却并不简单。Zookeeper使用了Zab协议,该协议包含两个可以无限重复的阶段: 阶段1:领导者选举 集合体中的所有机器通过一个选择过程来选出一台被称为"领导者"的机器,其他的机器被称为"跟随者"。一旦半数以上的跟随者已经将其状态与领导者同步,则表明这个阶段已经完成。 阶段2:原子广播 所有的写请求都被转发给领导者,再由领导者将更新广播给跟随者。当半数以上的跟随者已经将修改持久化之后,领导者才会提交这个更新,然后客户端才会收到一个更新成功的响应。这个用来达成共识的协议被设计成具有原子性,因此每个修改要么成功要么失败。这类似于数据库中的两个阶段提交协议。 如果领导者出现故障,其余机器会选出另外一个领导者,并和新的领导者一起继续提供服务。随后,如果之前的领导者恢复正常,便成为一个跟随者。领导者选举的过程非常快,根据一个已发表的结果来看,只需要200毫秒,因此在领导者选举的过程中不会出现性能明显降低。 一致性 对于Zookeeper来说,理想的情况就是将客户端你都连接到与领导者状态一致的服务器上。每个客户端都可能被连接到领导者,但客户端对比无法控制,甚至它自己也不知道是否连接到领导者。
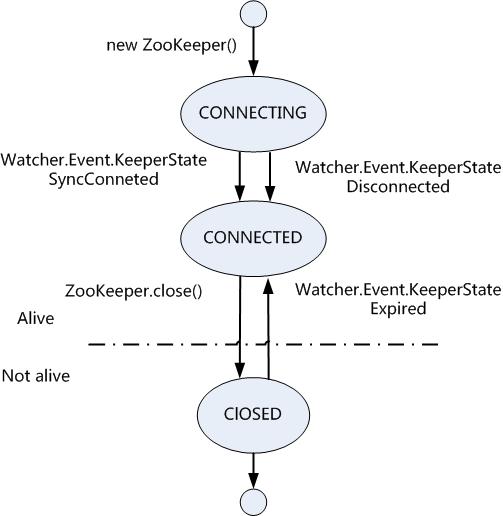
在Zookeeper中设计中,以下几点考虑保证了数据的一致性。 顺序一致性:来自任意特定客户端的更新都会被其发送顺序被提交。也就是说,如果一个客户端将znode z值更新为a,在之后的操作中,它又将z值更新为b,则没有客户端能够在看到z的值是b之后还能看到z值是a。 原子性:每个更新操作要么成功,要么失败。这意味着如果一个更新失败,则不会有客户端看到这个更新的结果。 单一系统映像:一个客户端无论链接到哪一台服务器,它看到的都是同样的系统视图。这意味着,如果一个客户端在同一个会话中连接到一台新的服务器,它所看到的系统状态不会比之前服务器上看到的更老。当一台服务器出现故障,导致它的一个客户端需要尝试连接集合体中其他的服务U奇时,所有滞后于鼓掌服务器的服务器都不会接受该链接请求,除非这些服务器赶上故障服务器。 持久性:一个更新一旦成功,其结果就会持久存在并且不会被撤销。这表明更新不会受到服务器故障的影响。 及时性:任何客户端所有看到的系统视图的之后都是有限的,不会超过几十秒。这意味着与其允许一个客户端看到非常陈旧的数据,还不如将服务器关闭,强迫客户端连接到一个状态交心的服务器。 会话 每个Zookeeper客户端的配置中都包括集合体中服务器的列表。在启动时,客户端会尝试连接到列表中的一台服务器。如果连接失败,它会尝试连接另一台服务器,一次类推,直到成功与一台服务器建立连接或因为所有Zookeeper服务器都不可用而失败。 一旦客户端与一台Zookeeper服务器建立连接,这台服务器就会为该客户端创建一个新的会话,每个会话都会有一个超时的时间设置,这个设置由创建会话的应用来设定。如果服务器在超时时间段内没有收到任何请求,则相应的会话会过期。一旦一个会话过期,就无法重新打开,并且任何与该会话相关联的短暂znode都会丢失。会话通常长期存在,而且会话过期是一种比较罕见的事情,但对应用来说,如何处理会话过期仍是非常重要的。 Zookeeper客户端可以自动地进行故障切换,切换到另一台Zookeeper服务器,并且,关键的一点是,在另一台服务器接管故障服务器之后,所有的绘画(和相关的短暂znode)仍然有效。 在故障切换过程中,应用程序将接收到断开连接和连接至服务器的通知,当客户端断开连接时,观察通知将无法发送,但是当客户端成功恢复连接后,这些延迟的通知会被发送。当然,在客户端重新连接到另一台服务器的过程中,如果应用程序试图执行一个操作,这个操作就会失败,这充分体现了Zookeeper应用中处理连接丢失异常的重要性。 状态 Zookeeper对象在其生命周期中会经历集中不同的状态,你可以在任何时候通过getState()方法来查询对象的状态: public states getState() Zookeeper状态转化图:
转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |