京东618:京麦微服务技术架构演变之下的618备战实践
|
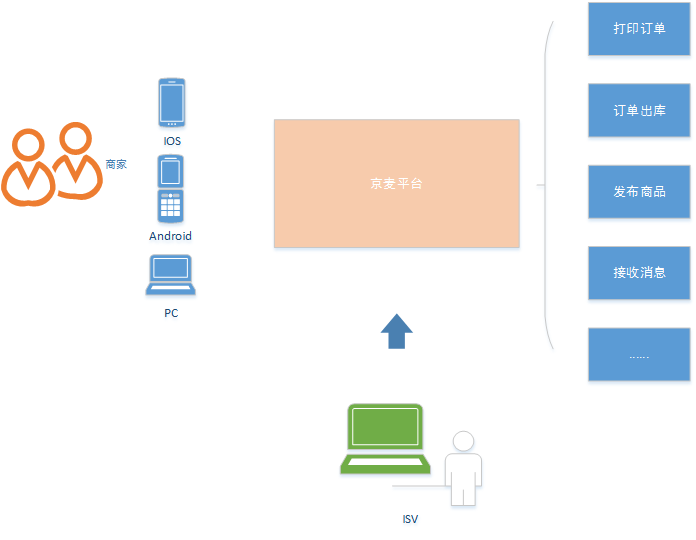
序 京麦工作台是京东十万商家唯一的店铺运营管理平台。京麦服务技术架构从早期的单一nginx+tomcat部署,到现在的单一职责,独立部署,去中心化。期间团队开发了JSF/HTTP等多种协议下的网关、TCP消息推送、APNs推送、降级、限流等技术,如今京麦服务架构已然走在了微服务之路上,但微服务是软件架构的银弹吗,组件以服务的形式提供之后给我们的618备战提出了哪些挑战。本篇文章将深入解析京麦微服务技术架构演变之下的618备战实践。 正文 作为技术研发人员,我们常戏称京东每年只干两件事,一个是618,另外一个是11.11。确实每一次的大促都是一场全兵演练,技术人员在这场战斗中,从团队合作、技术提升、用户意识上都有一个立体的提高。实难想象还有比这样规模的促销再有更好的锻炼方式。 京麦平台是目前京东所有商家唯一使用的一站式店铺运营管理平台,商家借助京麦可以实现商品发布、打印订单、出库、订单消息接收等等一系列的日常工作,京麦平台更是集合了众多 ISV 厂商为商家提供了更加丰富的功能,更好的赋能于商家。
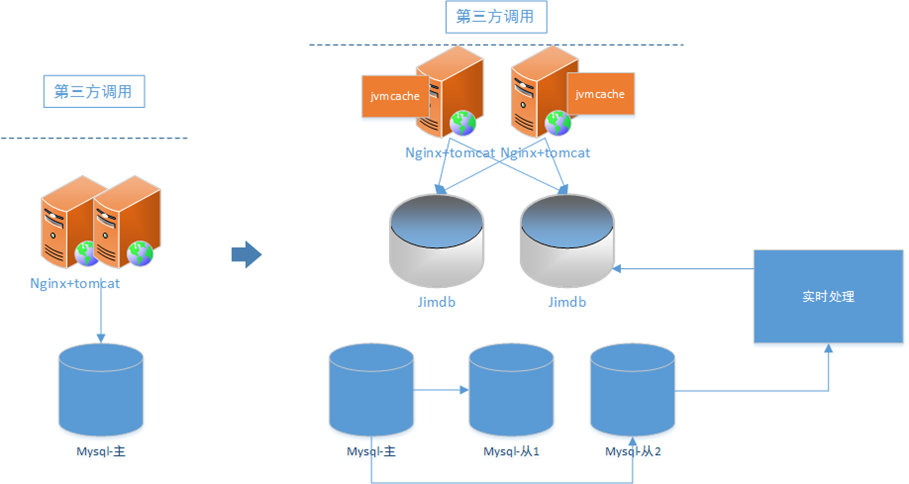
京麦平台的技术架构也在随着京东业务的飞速发展不断演化着。从早期的简单 nginx+tomcat 部署,到现在功能服务模块化,独立部署,享受着微服务带来的便利,但同时也给我们大促的备战带来了几多挑战。
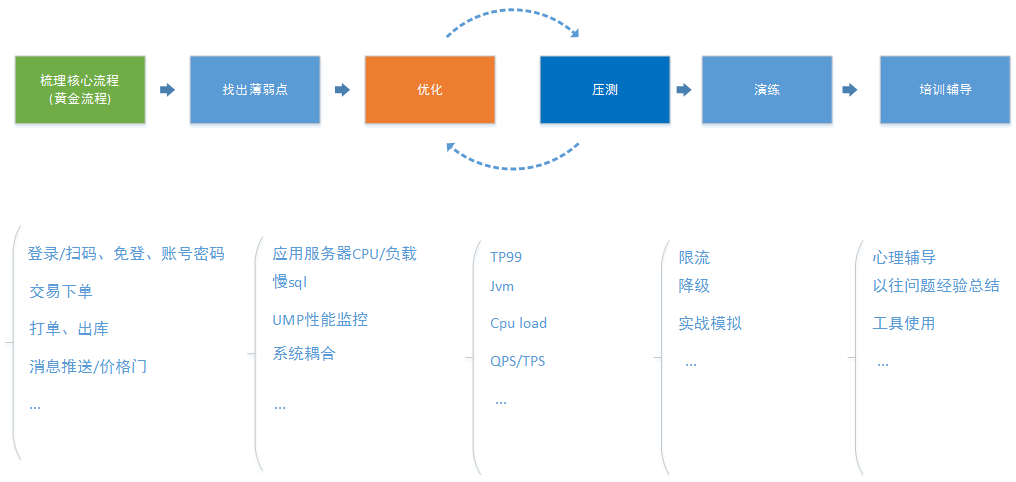
备战618,首先确定自己的备战思路,梳理核心流程、找出薄弱点,对薄弱点具体优化,同时协调压测对优化结果验证,优化和压测会有一个反复的过程,后面我们还要实际演练,比如降级开关,防止实际情况发生的时候准备好的功能不可用,最后我们要做一轮培训,在工具使用,快速定位问题,历来的教训总结都过一遍,从心理层面上我们也要辅导,大促期间发生的问题都不是小问题,研发人员在这种压力下处理问题有时候会变形,我们会在这方面做一次心理疏解。 这中间我们可以利用几个规则,二八法则,找出20%重要核心的功能,比如京麦的登录、交易、价格门消息推送。在找薄弱点的时候我们可以试试康威定律的几点规则,“可能出错的事总会出错”,“如果你担心某种情况发生,那么他就有可能发生”,最后我们还会找大家一起列出你心中最不可能出现问题的系统和功能点,那么列出来重点对待,没错,是重点对待。
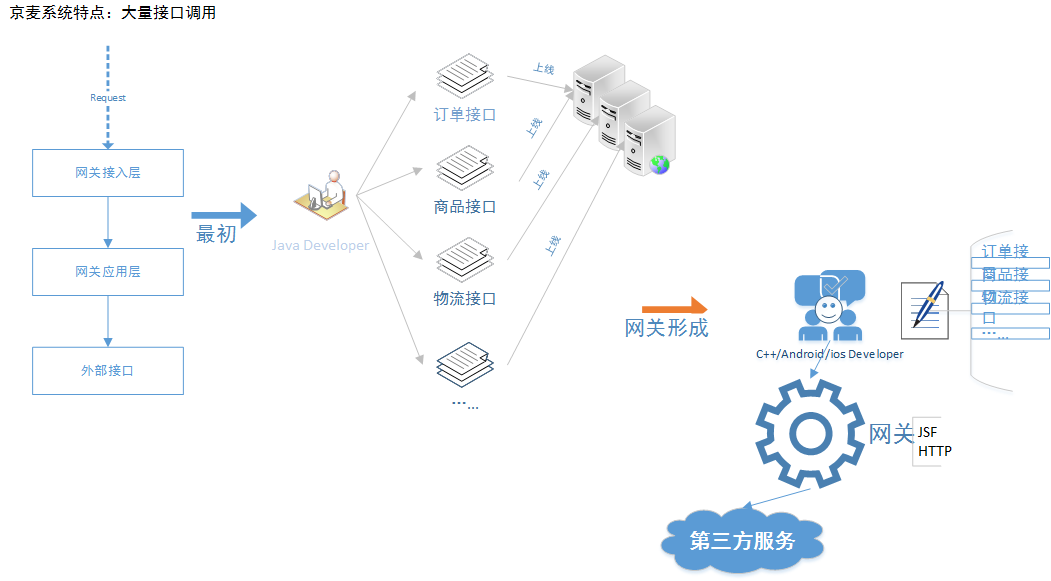
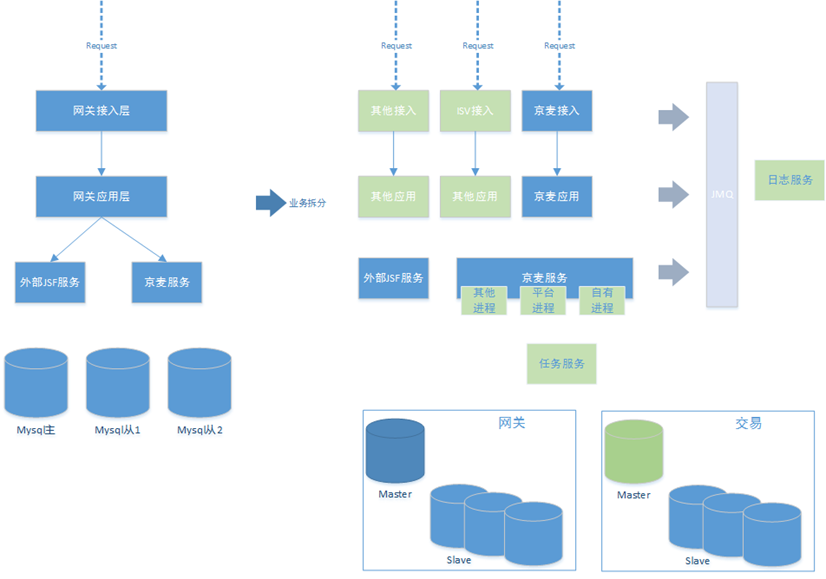
我们常用的备战技术,肯定不是重启,回滚,加机器。这里面个人总结有分离技术,缓存技术,SQL优化,快速失败,降级限流。我们来逐一介绍。 分离技术 话说“天下大事,合久必分,分久必合”,但在软件架构领域,一直是一个分的趋势,比如京麦平台有提供 ISV 的服务、提供京麦自有客户端的服务、提供其他平台的服务,同时还有监控服务,日志服务,消息服务等,需要将业务服务隔离部署,线下分析和线上运行隔离,同时还可以采取线程隔离,比如 JSF 里面为每个不同重要的服务分别一个线程组的方式。 <jsf:server id="jsf-upload" threads="5"/> 数据库层面上主从分离,京麦平台的业务都是读多写少,可以充分利用分库的资源。
还可以再将数据库细分,按照主要业务拆分不同的数据库,结合 RPC 使用,更大降低数据库层面的耦合程度。
缓存技术 如果软件里面真的有一种银弹的话,我认为就是缓存,当你性能优化遇到瓶颈的时候,当你想抗量的时候,你都会想到缓存。这里有一个铁律,那就是,对外暴露的接口一定不能直达数据库。我们常用的缓存是 redis+jvmcache。计算 redis 穿透率的时候我们可以,通过 UMP 来实现,在一个方法的总入口埋点,比如统计出1分钟调用 M 次,在请求 redis 的入口埋点,统计出1分钟调用 N 次,计算命中率:N/M。在使用 redis 的时候要注意含有大数值的 key,常常量一上来会造成 redis 集群的热点访问,直接将单一节点打死。这样的情况下我们就要拆分这样的大 key。同时将缓存 DB 化,就是不设置超时时间,这样全部用 redis 来抗量。本地缓存这块我们常用的有 Guava-cache,通过本地缓存我们可以做三级防护,或者做托底数据等。如果数据“尺寸较小”、“高频的读取操作”、“变更操作较少”使用这种嵌入式缓存将非常合适。
SQL优化 每次大促前我们都要将系统中性能慢的 sql 抓出来,而且这种工作投入产出比极高,也就是可以花费较小代价带来极大的性能收益。sql 性能问题,大多数情况下是没有索引引起的,这可能是后续业务变化迅速,上线前代码 review 的遗漏,需要这个时候统一过一遍。还有就是索引使用错误,比如索引字段是字符串类型,但是程序中请求 DB 的时候传的是 long 类型,索引失效,表中数量过多,做了一次全表扫描,性能会很差。 还有时候我们添加索引的时候要看区分度,计算索引区分度的方法,不重复的索引值/总记录数,值越接近1,说明区分度越高,查询的时候 mysql 就会过滤掉更多的行数据。还有,添加索引最好结合 mysql 执行计划来判断。有时候做了过多的 join 操作,比如超过3张表以上,我们就要想着去拆解这些 sql 语句。在就是数据库层面我可以把历史数据转出减少数据量来达到提高查询速度的目的。
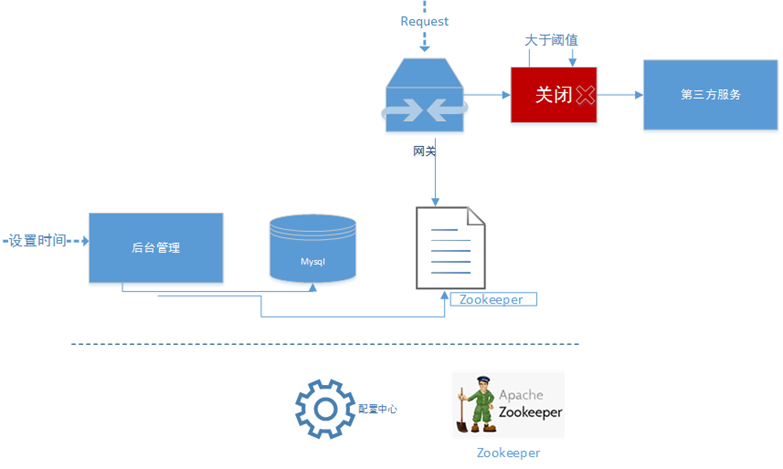
快速失败 快速失败策略实际上是一种自我保护措施,比如调用第三方接口超时,如果超时时间设置过长,访问量大的时候,就会导致请求线程积压,如果此时有线程隔离还好,若刚好没有,那么访问量一上来就会迅速导致 cpu 飙高。京麦平台的特点之一,会大量调用第三方接口服务,我们会对每个方法动态的设置超时时间,如果 UMP 报警再结合 JVM 性能数据,我们会将这个接口的超时时间阈值调小。通过 zookeeper 下发到每一个服务节点上。在大促前,我们会重点检查 mysql、redis、jsf 等 rpc 调用的超时设置,确保每一次 rpc 调用都要有上限阈值。
关于 RPC 调用超时,这里多说一下,有时候我们会发现调用端性能比如超过500ms,但是服务端确是在100ms上线徘徊。这里面我们除了检查网关延时,tcp 重传,还要注意一点,就是任何一个成熟的 rpc 框架都不会让业务线程直接参与网络请求,rpc 会提供一个消息队列,调用端直接跟消息队列打交道。此时,我们就要想到队列这块是否有问题了。 降级限流 这种技术实际上是保命的措施。降级一般有屛蔽降级和容错降级两种,对一些非核心的功能,比如京麦的麦圈,服务号,论坛等功能,而他们恰恰又请求着 mysql,redis 等公共资源,为了减少这种竞争我们就会对这些功能进行屛蔽降级,直接切断 RPC 调用,不再发起远程调用,返回空或者其它异常提示,减少公共资源的访问。 降级开关,目前京麦是采用统一配置中心来使用。同样,限流技术在京麦平台中也是异常重要的一个措施,尤其是对京麦网关的调用。我们目前是采用令牌桶的方法,实现方式是 Guava RateLimter,简单有效,再结合统一配置中心,我们可以动态调整限流阈值。不用重启服务器即可实现快速限流策略调整。我们在网关里面还有一个设置,就是并发度,这个是方法粒度的,对每一个调用第三方的接口都有一个并发度数值设置,而且是动态设置,也是通过 zookeeper 下发到每一个服务节点上。并发度的具体实现是通过 jdk 的 Semaphore。
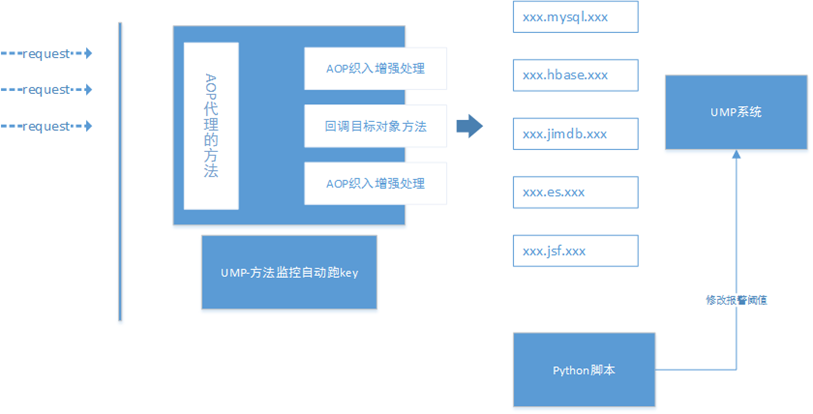
我们再来说一下,监控配置和性能压测。 监控配置是一定不能缺少,我们要求自己一定要第一时间早于用户发现问题。平时开发在上线的时候我们都应该有统一要求每一个 RPC 调用都要有监控和错误栈的输出。 在备战期间实际是对监控配置的一个治理过程,监控配置 key 要规则化,比如 ***.mysql.***,***.redis.*** 等让我们一眼便知到是操作的哪一个资源。京麦平台这次备战的过程中通过采用 AOP 的方式,把所有类似的调用统一规范化处理,后续结合 Python 脚本对监控阈值进行统一调整。这样走下来一方面把我们平时可能漏掉的监控给补全,另外一方面我们的监控配置按照统一的规则来生成。
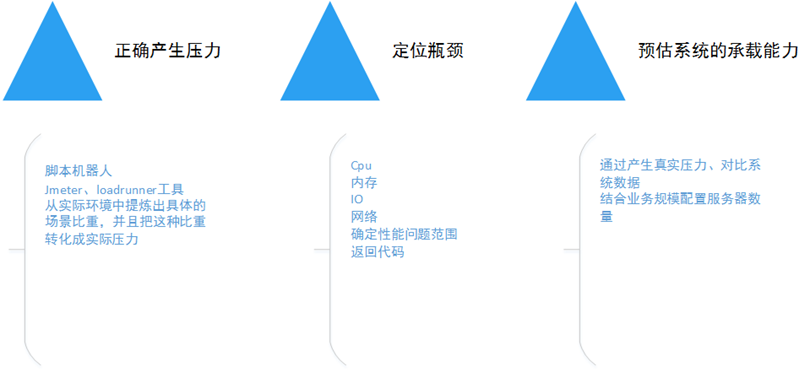
性能压测这一块,可以很好的检验我们优化的结果,压测的过程中我们关注 qps 的同时,还要结合服务器的 cpu、io、内存等机器性能指标来定位我们的性能瓶颈。最后来预估我们系统的承载能力,提供数据支撑来申请服务器或者 docker 资源。压测工具研发可以自己写脚本,借助 jmeter、loadrunner 等工具,也可以有计划的联系性能压测组他们协助执行。最困难的还是产生真实的压力。
还有一个备战点,返璞归真,回到代码,重点核心功能检查一遍,把坏味道的代码查出来。比如 join 了很多张表的 sql 语句,日志输出没有采用条件方式或者占位符的方式,日志重复打印,try 代码块放到了事务中,循环体中含有低性能的语句,锁代码块中进行 RPC 调用,等等。 最后,我们可以想一下备战备的是什么,总结历次的大促,我认为主要在,工具、知识、经验三个方面的备战。工欲善其事,必先利其器,我们要有一些个好的工具辅助我们解决问题,比如 MDC(里面含有 CPU,网络等监控)、UMP(京东自研方法性能,可用率等监控平台)、CAP(容器的总体监控,也含有 cpu 负载等信息查看)。知识层面,是我们历来的积累,我们的认识的提高,使用工具时候的指导。经验是我们以往的大大小小的教训的总结,前车之鉴,防止我们再次发生类似的事情。 以“结硬寨,打呆账”这句话结束此次618备战的总结,最重要的一点,还是要求我们备战在平时。 本文受原创保护,未经作者授权,禁止转载。 linkedkeeper.com (文/王新栋) ©著作权归作者所有 |