京东618大促网关承载十亿调用量背后的架构实践
|
618大促,我们的网关承载了几十亿的流量和调用,在这种情况下,网关系统必须保证整个系统的稳定性和高可用,保证高性能和可靠,以支撑业务。我们面临的是一个非常复杂的问题,基于这种复杂问题,怎样做到很好地提高它的性能和稳定性、复杂技术之间怎么整合保证整体网关的高可用,是本文的重点。 一、网关涵盖技术 1.1 网关系统 网关系统主要有两种:
这两种不同网关所使用的技术非常类似。 流量比较大的网关面临的难点包括: 第一,网关系统需要扛几十亿的流量调用,接口的平稳运行、每一个接口在后端服务之后的性能耗损都非常重要。比如我们使用了一个Redis集群,然后构建了两个机房,每一个机房都搭建了一个Redis集群,这样的话就能够很好地保证高可用。在面对一个瞬间流量的时候,我们采用了一些缓存技术,或者更前置的Nginx+lua+Redis技术,让这种大流量应用能够脱离开JVM的依赖。还有我们需要梳理各个接口,通过降级的策略把一些弱依赖的接口进行降级,从而保证核心应用的可用。 第二,网关系统其实就是一个把Http请求拓展到后端服务的过程。我们的网关承接了一千以上的后端服务接口,面对这种情况,怎样做到服务与服务之间相互不影响?架构层面怎样能够杜绝蝴蝶效应、防止雪崩?就是说当一个接口出现问题的时候,不至于影响到其他接口的健康运行。这个说起来简单,但实际却不然。 一千个以上的接口,每个接口性能都不一致,而且每个接口所依赖的外部资源、数据库缓存等都不一样,几乎每天都会出现各种各样的问题,我们怎样通过一些隔离技术、治理技术等,保证当这些接口出现问题的时候,不会影响到全局? 第三,我们对外暴露了一千个服务接口,所有接口的后面意味着几十个甚至上百个团队每天在不停地开发,每天都可能上线新的需求。面对这么复杂的情况,我们不可能每次后端服务器有任何修改,都需要有网关的修改或上线,这样网关会变得非常脆弱,稳定性极低。 我们采用了一个动态接入的技术,让后端的网关能够通过一种接入的协议进行无缝接入,之后通过一些动态代理的方式,直接让后端的接口,不管做任何修改或上线,都可以通过后端管理平台从网关上对外进行透传发布,很好地解决了我们网关所面临的依赖于后端接口服务的上线问题。 1.2 网关涵盖技术
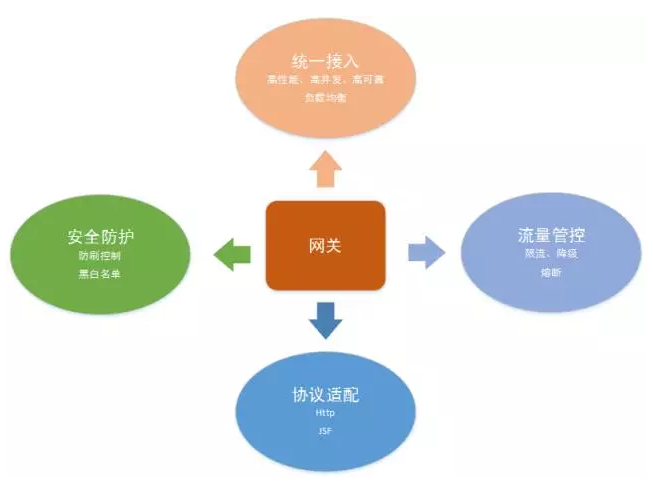
网关的四个技术方向: 第一,统一接入。就是前端(包括APP或其他来源)的流量,能够都在统一网络层进行接入。这一层所面临的问题是:高性能透传、高并发接入、高可效性,以及当前端流量来了之后,怎样能够进行一个负载的往后端的转发。 第二,流量管控,主要指流量治理部分。面对海量流量,我们怎样通过一些防刷技术,保障网关不被大流量冲垮;以及怎样通过一些像限流、降级、熔断等技术,对网关进行全方位保护。 第三,协议适配。就是前文提到的,网关会透传后端上千个服务,而这些服务一定不是每一个都需要网关去开发配置的。我们通过一个协议适配的转换,让后端的各种服务通过我们指定的协议、通过http的方式从网关开放出去,当然网关不单单是http协议,还有一些TCP的。京东内部的协议相对比较统一,有Http的restful的协议,也有JSF的接口,JSF是京东内部自研的一个框架,一个RPC调用框架,和double是类似的,然后基于注册发现的一个rpc框架。 第四,安全防护。这一部分对于网络来说非常重要,因为网关是整个公司对外的一个出口,在这一层我们要做一些防刷,比如防清洗一些恶意流量、做一些黑名单,当有一些恶意流量的话,通过限制IP等限制手段把它拒绝在整个网关之外,防止这些恶意流量把网关冲垮。 二、自研网关架构
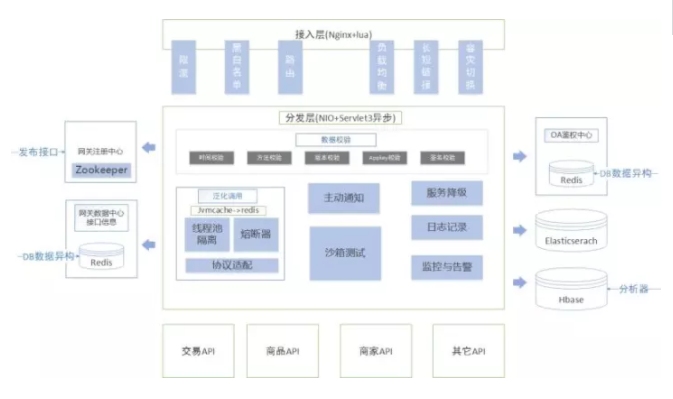
2.1 自研网关架构 我们的自研网关架构主要分为三层。 第一层:接入层。主要负责一些长短链接的接入、限流、黑白名单、路由、负载均衡、容灾切换等。这一层所采用的技术是Nginx+lua的方式。 第二层:分发层(或者叫:网关的业务层)。它更多的是NIO+Serviet3异步的技术。在这一层中又分为几个部分。
泛化层中间有两块:一个叫主动通知,另一个是沙箱测试。主动通知很好理解,就是我们会通过这种TCP的下行通道及时通知到客户端,发一些像京东账户优惠券或提醒等;沙箱测试主要是说我们在一些接口发布上线之前,进行一个外部的测试。 如图,最右侧部分是服务降级、日志记录、监控告警,这三个都是我们整个网关的支撑系统。服务降级是说当有些服务出现问题,第一时间把它降调;日志是给我们排查问题用的;监控告警在下文会重点介绍,因为一个网关的可用性很大方面是通过监控系统来完善的,没有监控系统、没有告警,就像没有眼睛一样,没办法知道任何事。 第三层:后端各种各样的业务API(业务接口)。这些接口通过网关对外进行暴露。 整个网关大体上分为以上三层,最上面的接入层、中间是网关的分发层,以及业务校验、业务逻辑层,然后通过网关透传请求到后端服务。 除了这三层之外,我们再看两边的系统,都是我们整个网关比较核心和重要的支撑。
2.2 技术栈 我们的网关系统所涉及到的一些技术栈:第一是接入层Nginx+lua技术;第二是NIO+Serviet3异步的技术;第三是分离技术;第四是降级限流;第五是熔断技术;第六是缓存,哪些地方该加缓存,哪些地方可以直接读库;第七是异构数据;第八是快速失败;最后是监控统计,这是整个高可用网关系统里非常重要的一部分。 下文会针对这些技术所适用的场景进行深入探讨和分析,包括我们用这些技术解决什么问题。 三、基本思路及过程改进点 实践 1 Nginx层统一接入
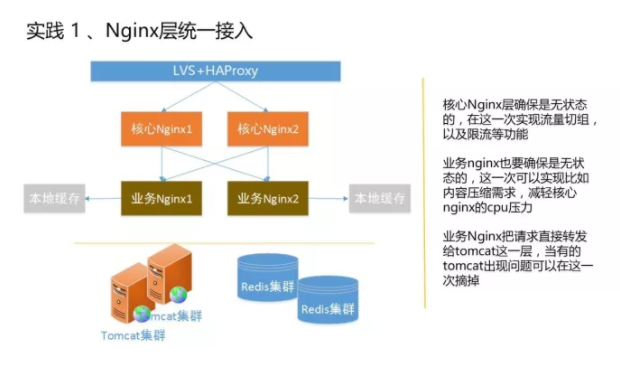
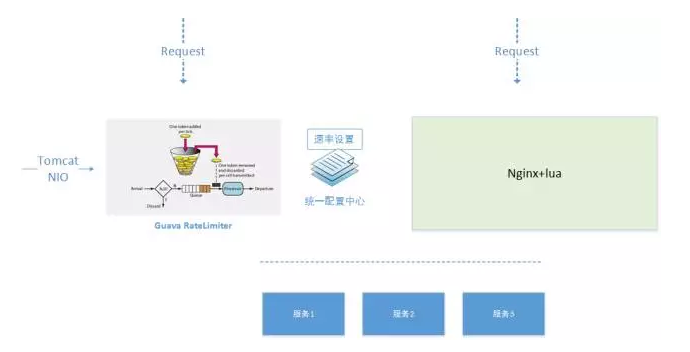
先看网关整个线上的部署架构,先通过一个软负载LVS进入到整个京东的网关,第一层是核心Nginx,经过核心Nginx之后就是后面的业务Nginx,然后通过业务Nginx把我们的请求透传到后端的服务器。 核心Nginx主要是前端流量的分配,比如限流、防刷都是在这层去做。下层是业务Nginx,主要的Nginx+lua的逻辑在这一层实现。这一层还有能减轻核心Nginx压力、CPU压力的作用,而且一些lua的应用逻辑,比如限流、防刷、鉴权、降级都是在这一层做的。 为什么要加上Nginx+lua这一层?相较于Tomcat等,Nginx其实是一个能扛特别大并发流量的服务器。基于这种状况我们之前出现过问题,当这种并发流量特别大的时候,一旦后面出现单个机有问题,哪怕你针对这个接口做了降级,但其实真正流量还是到了Tomcat层的JVM里,当流量很大的时候,很难通过JVM去消化掉这块东西,这样导致的结果是:当你的Tomcat出现问题了,你很难通过重启去解决这个问题,因为流量会一直存在,这台Tomcat出问题了, 重启完之后是把所有行动都释放了,但是它们就像病毒一样,会来回传染,你重启了一批,这批马上又被传染到。Nginx天然就是这种NIO异步的方式,能够非常好地支持大并发的业务需求。所以我们把一些核心的,比如降级、流控等,都放在这一层,让它替我们在最前端把流量防住。 实践 2 引入NIO、利用Servlet3异步化
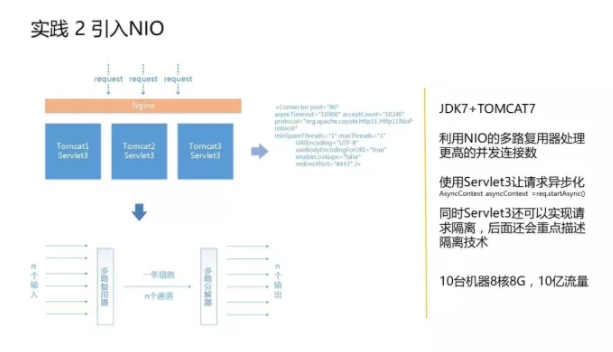
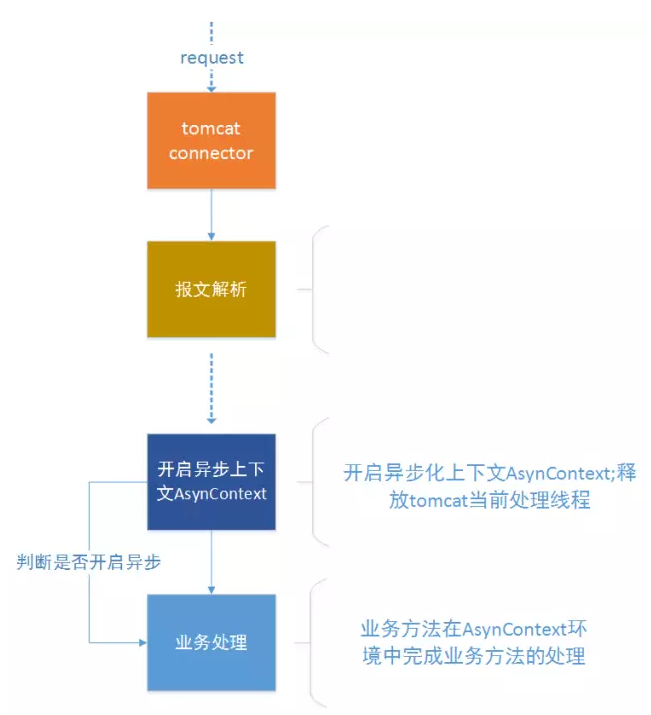
第二个实践是在Tomcat层引入了NIO,用了一个JDK7+TOMCAT7+Servlet3的配置,让同步请求变得异步化,然后利用NIO的多路复用处理技术,让我们能够同时处理更高的并发数。
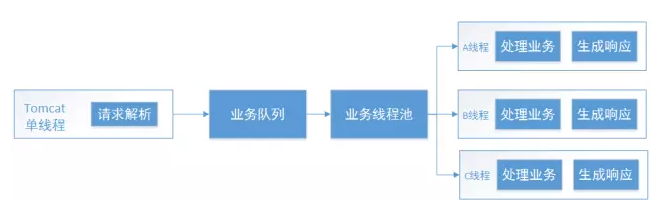
利用Servlet3异步化之后可以提升吞吐量,但单个请求的响应时间会略微变长,不过这种损耗是可以忍受的,因为这会带来整个应用吞吐量的增加和灵活性的增强。还是非常值得我们使用的。 具体采用策略:业务方法开启异步化上下文AsynContext;释放tomcat当前处理线程;tomcat该线程被释放,然后用于下次请求的处理,提高其吞吐量;在AsynContext环境中完成业务方法的处理,调用其complete方法,将响应写回响应流。这样可以提高tomcat业务逻辑的可能性,让我们在这一层非常少的线程数就能处理更多的请求,而不至于当流量非常大的时候会被压垮。 实践 3 分离之术 本节将在所有分离技术中挑两个比较重点的进行分享。 请求解析和业务处理分离 第一个是通过NIO的方式,把请求解析的线程和后面处理的业务线程进行分离。
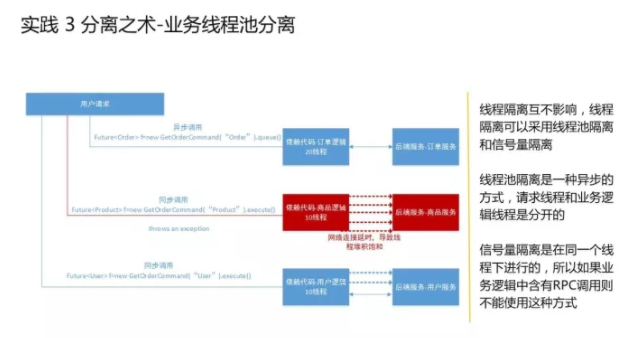
请求由tomcat单线程处理,在NIO模式下可以用非常少量线程处理大量链接情况。业务逻辑处理和生成响应都是由另外的tomcat线程池处理,从而跟请求线程隔离。这里的业务线程池还可以进一步隔离,不同业务设置不同的线程池。 业务线程池分离
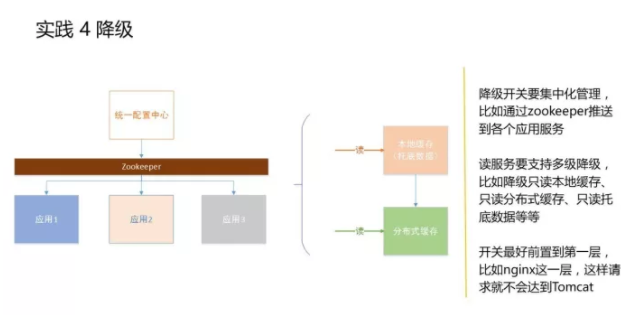
第二个是业务线程池分离,就是通过一个线程的隔离技术,把不同的接口或不同类型的接口进行隔离。比如订单相关的接口,拿20个单独线程去处理;商品相关的接口,拿10个单独的线程去处理,这样的话就可以让不同的接口之间互不影响,如果订单这块有一个出了问题,最多消耗它自己,不会影响到其他接口的线程的调用。 具体的线程隔离可以根据业务来指定一组线程的数量,这几个线程是为固定接口准备的,当这个接口出现问题,它就把自己的线程数用掉了,不会去占用其他接口的线程,这样起到了线程隔离的作用,让单个API出问题的时候不会影响到其他。 实践 4 降级 降级主要是说当有某个接口出现问题,我们能够把这个接口直接降调,让它调用直接返回,不会用到其他应用。还有就是如果某一块弱一点的业务逻辑出现问题,我们直接把这块逻辑降调,不至于影响到其他的黄金逻辑。 降级怎么做?
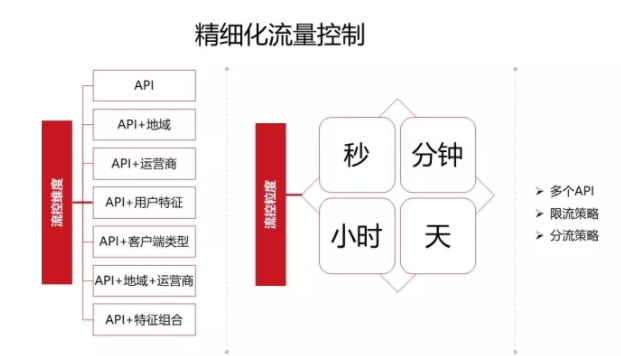
首先,降级开关要集中化管理,比如通过zookeeper推送到各个应用服务。这样才能在出现问题的第一时间找到对应开关做降级处理。 一个基于开发降级的统一配置本身这个系统要是高可用的、支持多维度的缓存,比如我们如果用zookeeper实现,首先zookeeper会有数据库存储,再上面会有一个本地缓存。再就是我们会有一个快照,如果zookeeper读不到缓存,会通过快照去加载进来一些托底的数据,以保证开发一旦触发之后能够在第一时间响应。而我们的开关也不至于会成为其他系统的问题,它是非常弱化、非常薄的一层。 精细化流量控制
说完开关、流量控制和降级之后,我们来看通过多维度的流量控制和降级的策略,比如按照单个API或API+地域、运营商等维度进行控制。一旦出问题了,我们会把多种组合方式进行降级,还可以根据秒/分钟级等不同维度进行流量控制,从而达到精细化流量管理。 优雅降级
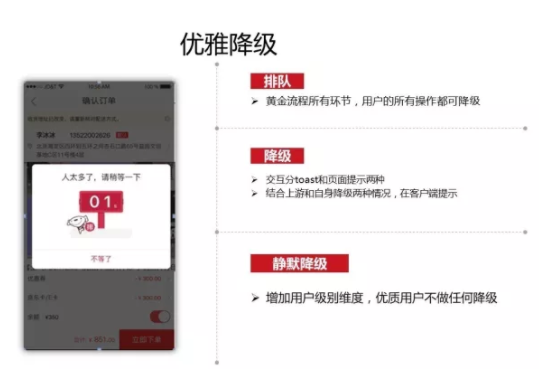
说到降级,前面说的更多的是技术层面的,在业务层面的话,我们也要讲究优雅降级。我们不能说这个逻辑一旦建立之后就直接返回前端502,这肯定是不友好的。我们肯定会跟前端进行沟通,比如降级之后反馈给前端一个对应的错误码,或者给用户反馈一个提示等操作指令,这样能够让用户体验更好一些。 实践 5 限流
恶意请求、恶意攻击,恶意的请求流量可以只访问cache,恶意的IP可以使用nginx层的 deny进行屛蔽; 防止流程超出系统的承载能力,虽然会预估但总有意外,如果没有限流,当超过系统承载峰值的时候,整个系统就会打垮。 实践 6 熔断
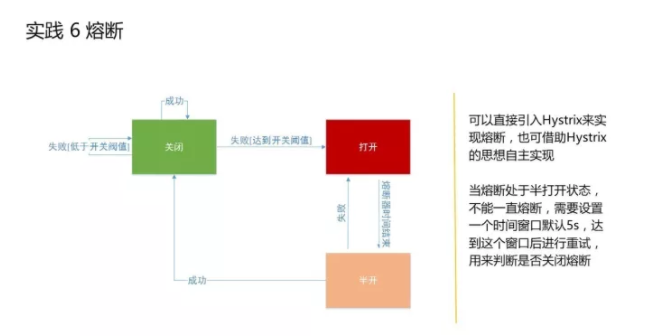
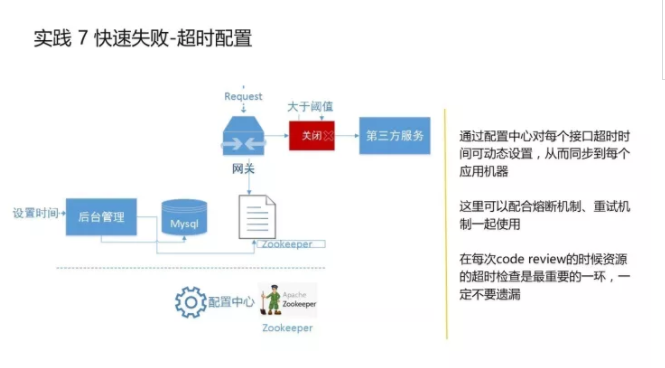
当我们的后端机构出现问题了,达到某个阀值了,系统就能够自动进行关闭降级,这是熔断的大体思路。我们会有更灵活的配置:比如当某个接口接连三次访问超时或返回错误的话就自动熔断;也可以是配置一些超时间,比如连续三次这种方法调用的性能都超过了50毫秒,就会自动对这个方法进行熔断,熔断之后就相当于降级了,再次调用的话会返回失败,就是直接拒绝返回了。 熔断之后还可以有一个设置:比如5秒或一分钟之后出来一个半打开状态,再次醒来之后,它会去试探一下当天这个服务是否已经OK了,如果没有问题了,它就会去把你之前熔断的API业务再次打开,能够正常对外提供服务。现在有一些开源的实践,通过这些实践可以很好的做熔断,当然根据这里边的思路,自己也可以实现,这不是特别复杂的事情。 实践 7 快速失败-链路中的超时
快速失败是非常重要的一个实践,不光是做网关系统,做其他系统也要记住,特别是调用量大的系统,比如注意到整个链条中的超时设置。这是我们每年在做双11和618备战的时候,都需要重点去review的一块东西,包括我们平时在做开发的时候、每一次新模块上线之前,我们都要重点去监控这一块。我们会梳理所有系统对外的依赖,比如网关依赖于我们自己的一些业务的缓存、数据库,更多的是依赖于后端数千个不同的服务。 这种涉及到网络的,我们必须要设置超时间,因为像网关这种调用量比较大的系统,如果不设超时间,有可能它默认时间就是几分钟,这么长时间,一旦有一个机构出问题了,有可能瞬间整个网关系统会全部雪崩掉,任何一个接口都不能对外使用,因为数据量很大,有可能你都来不及降级就已经被冲垮了。
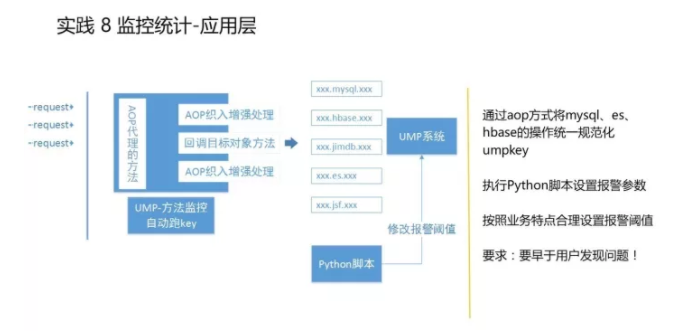
实践 8 监控统计-应用层
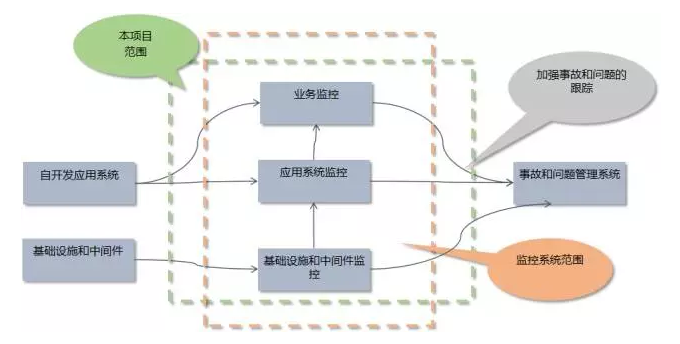
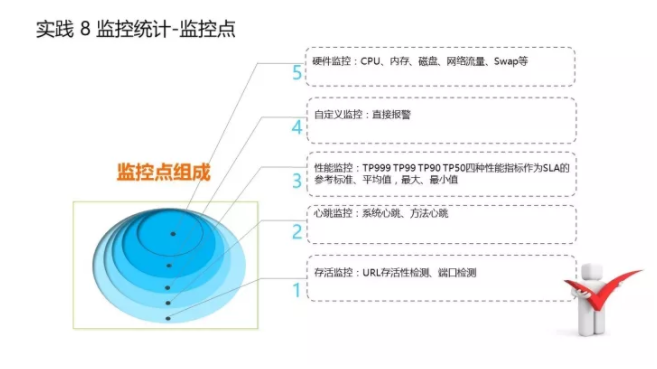
监控统计是网关系统里非常核心的一部分,只有有了监控,有了报警,才能让我们实时了解所有的运营情况、每一个API调用的情况。 监控目标 第一:保证7*24小时守护系统; 第二:能够实时监控系统的运营状况,比如哪个API是不是调用时间过长了?哪个API已经熔断了?等等; 第三:统计数据,分析指标。比如一天过去了,每一个API调用情况有没有超时?有没有访问的性能降低等; 第四:实时报警。因为监控是一部分,发现问题之后能够第一时间通知到我们,让我们能够马上处理也是让系统更加健康的一个方面。 监控范围
监控的维度
在京东内部有一个很完善的监控体系,叫UMP系统,能够帮助我们做各个层级的监控。它主要是提供给我们一些类似于配置的文件,我们配置好之后就可以进行系统的监控,我们在做的时候会通过一些AOP代理的方式,对所有的方法进行监控。因为我们是网关,需要大量的后端透传,网关因为是动态地生成这些接口,根本不知道有哪些接口,所以在动态生成接口的时候自动地AOP给它注入一个个监控,这样的话就是每一个接口都能够有一个监控。 说到监控不得不提的是,我们做网关系统就是做透传的,后面有各种各样不同的接口、业务逻辑,每个业务逻辑和接口的性能都需要去监控,然后告知对方让对方去整改的,所以我们除了把这些监控加完之后,有了问题要能够通知到对应的负责人,包括我们自己。所以我们每一天每一周都会有邮件以报表形式发出,让所有系统负责人都知道对应的机构的情况,比如性能是否有问题、是否需要整改等。 本文受原创保护,未经作者授权,禁止转载。 linkedkeeper.com (文/王栋) ©著作权归作者所有 |