Technology Sharing of JingMai
|
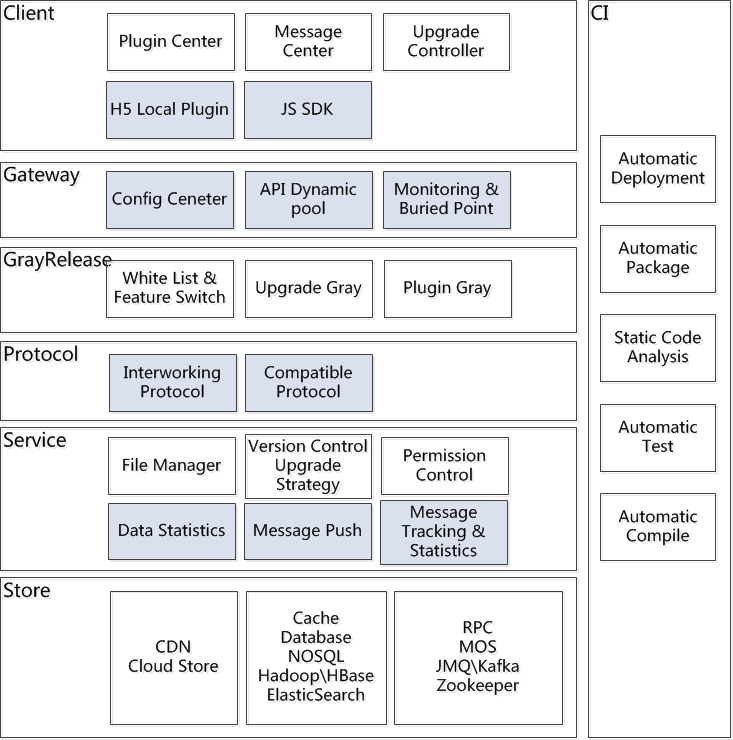
Technology Sharing of JingMai From the following chart, just list some of the core functions of JingMai, and each of the functions have a lot of expansion.
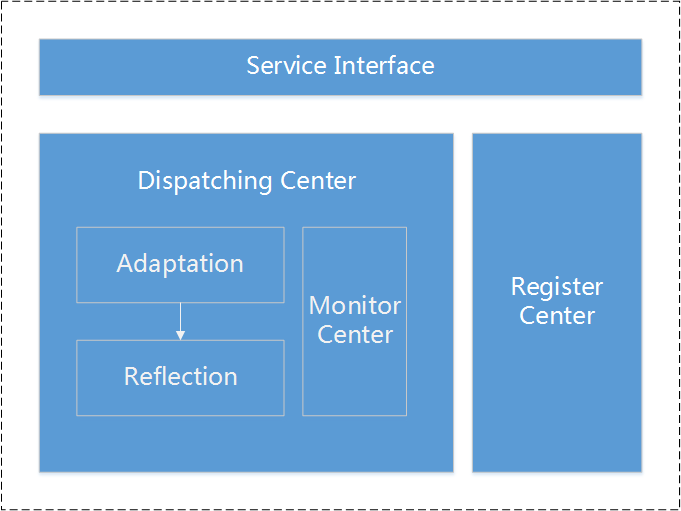
First, closely related to the business functions include: plugin center, message center, upgrade controller, and file manage, version control & upgrade strategy, permission control. Secondly, the functions of technological innovation include: H5 local plugin & JS SDK, gateway, compatible protocol and interworking protocol, buried point & data statistics, message push, message tracking & message statistics, which uses a lot of advanced technologies, including big data, rpc framework and message framework. And, we also have a great achievement in the CI, has been implemented to automatically compile, test, static code analysis, packaging, deployment. GateWay Gateway is one of the core functions of the JingMai, it is responsible for providing client interface calls. The Gateway registers the interface config to the Gateway through the Registration Center. When the client calls the Service Interface, it can automatically generate the interface instance through the Adaptation and Reflection of the Dispatching Center, so that the real service support can be achieved.
Register Center of GateWay Registration center using Zookeeper as a configuration center. As we know, the gateway needs a stable configuration management system when data changes can be immediately notify the gateway to update the API. At first, I used the message notification and polling database of two ways to try, but I found they are not suitable for the application scenarios. Finally, I chose the Zookeeper, because its listening mechanism. It's like a subscribe publish design patterns. If I listen a node path of Zookeeper, when the node data changes occur, Zookeeper will notify the client through the Wahter.
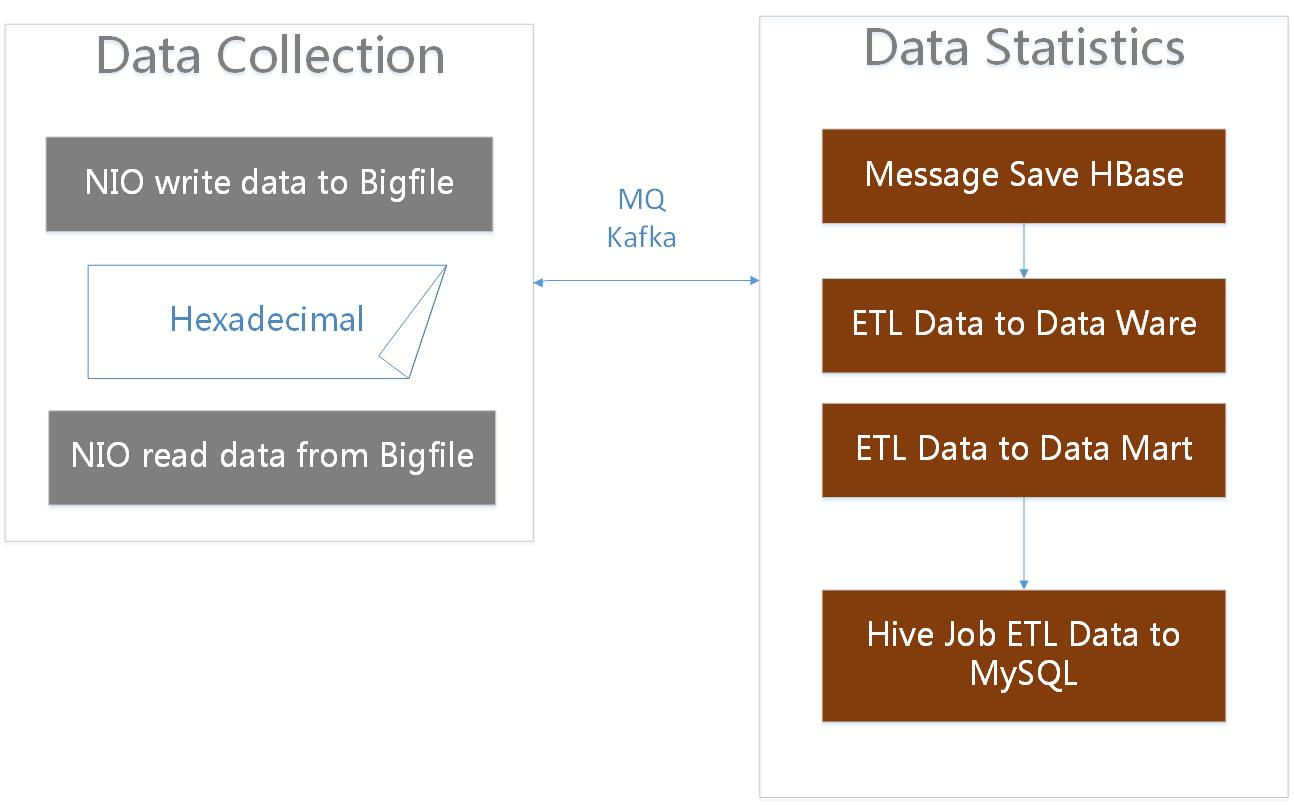
Registration center of gateway has mainly two functions: write data and read data. We designed different policies for write data and read data to ensure the success. When write data failure, the failure data will be write to small files, and the small files will assigned to different folder by hash. The files will be regularly scanned and reloaded. When read data, will read from the memory at first, if there is no data in memory, will connect the Zookeeper to obtain data, then save data to memory and local snapshot. When data changes, through the Watcher to update memory and local snapshots. The advantage of this design is, read data from the memory instead of from Zookeeper of every time. Secondly, if Zookeeper cluster is down, will not affect the client, even if the client is restarted, the client can normal start from a local snapshot of the disaster recovery. Buried Point & Data Statistics Buried Point & Data Statistics are composed of two parts: data collection and data statistics. Data Collection is responsible for send the data to the data collection terminal, the terminal receive the data, store data, convert data, and generate the final statistics.
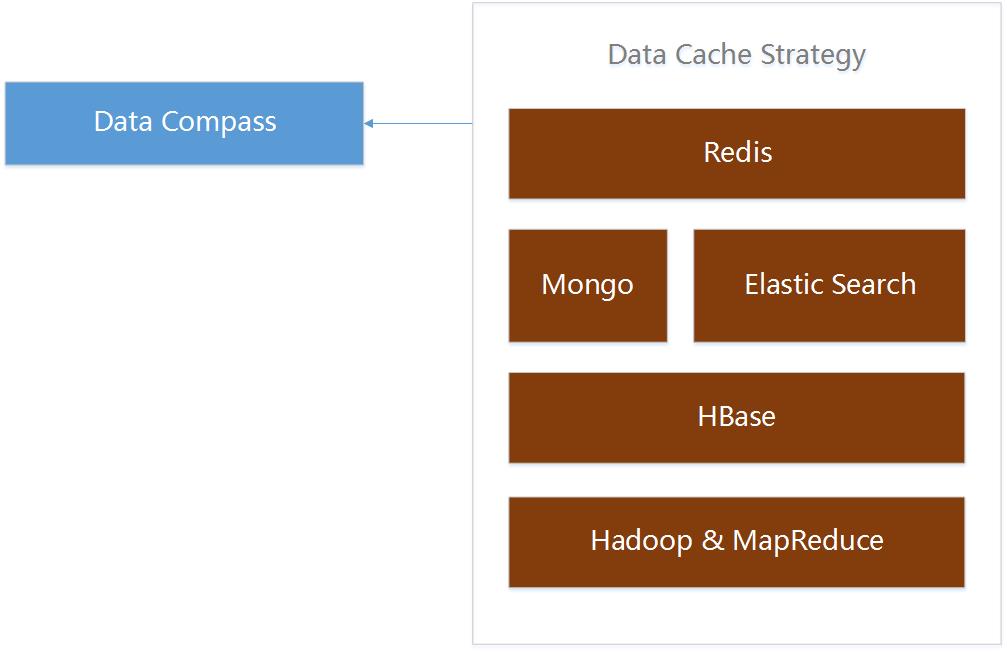
Data collection will put the data into the memory queue at first, then data is converted as hexadecimal asynchronous stored in large files through NIO. Files include metadata files and data files, when read data will update the metadata files at the same time. If the client is restarted, the metadata file is re loaded, and the data can be retrieved from the last position. Data is sent to the data collection terminal through the MQ or Kafka, when the data is received, it is stored in the HBase at first, then synchronized to the Data Ware and Data Market by increment, and finally, we extract the data to the database by the Hive Job. Data Cache Strategy of Data Compass of Plugin Data Compass provides a full range of data services, including store analysis and industry data. This is a mobile phone plugin, need to show a lot of data, reports and charts on a small screen, one chart may involve more than one business dimension and time dimension.
How to ensure the loading speed of data? We design different cache strategies for different forms of data, use data warehouses and markets to store the basic data, use HBase to store the theme data, use mongo or elastic search to store the dimension data and intermediate data, and use redis to store the buffer data. 本文受原创保护,未经作者授权,禁止转载。 linkedkeeper.com (文/Frank) ©著作权归作者所有 |