

常用推荐算法介绍——基于内容的推荐算法
|
1. 基本概念 基于内容的过滤算法会推荐与用户最喜欢的物品类似的那些。但是,与协同过滤算法不同,这种算法是根据内容(比如标题、年份、描述),而不是人们使用物品的方式来总结其类似程度的。例如,如果某个用户喜欢电影《魔戒》的第一部和第二部,那么推荐系统会通过标题关键字向用户推荐《魔戒》的第三部。在基于内容的过滤算法中,会假设每个物品都有足够的描述信息可作为特征向量(y)(比如标题、年代、描述),而这些特征向量会被用来创建用户偏好模型。常用的有决策树、神经网络和基于向量的表示方法等。 2. 特点 (1)基于内容的用户资料需要用户的历史数据 (2)用户资料模型可能随着用户的偏好改变而发生变化 3. 实现原理 假设我们有一些用户已经表达了他们对某些书籍的偏好,他们越喜欢某本书,对这本书的评分也越高(评分范围是1分到5分)。我们可以在一个矩阵中重现他们的这种偏好,用行代表用户,用列代表书籍。
图一:用户书籍偏好所有偏好的范围都是1分到5分,5分是最高的(也就是最喜欢的)。第一个用户(行1)给第一本书(列1)的评分为4分,如果某个单元格为空,代表着用户并未对这本书作出评价。 在基于内容的协同过滤算法中,我们要做的第一件事就是根据内容,计算出书籍之间的相似度。在本例中,我们使用了书籍标题中的关键字(图二),这只是为了简化而已。在实际中我们还可以使用更多的属性。
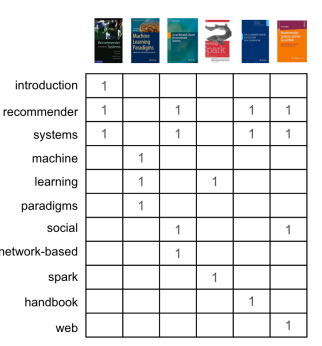
图二:用户已经评论过的书籍标题 首先,通常我们要从内容中删除停止词(比如语法词、过于常见的词),然后用代表出现哪些词汇的向量(或数组)对书籍进行表示(图三),这就是所谓的向量空间表示。
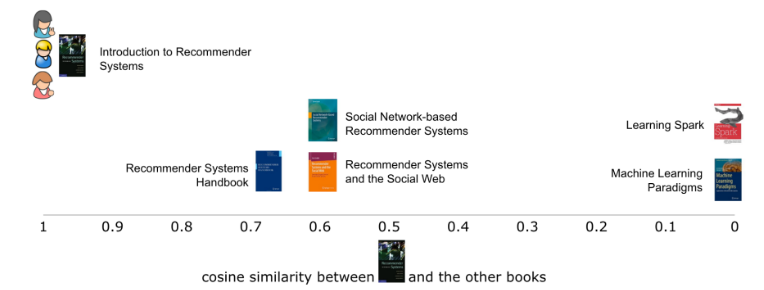
图三:使用标题的词汇如果在标题中有这个词,我们以1为标记,否则为空。 有了这个表格,我们就可以使用各种相似指标直接对比各本书籍。在本例中,我们会使用余弦相似点。当我们使用第一本书籍,将其与其他五本书籍对比时,就能看到第一本书籍与其他书籍的相似程度(图四)。就像大多相似度指标一样,向量之间的相似度越高,彼此也就越相似。在本例中,第一本书与其他三本书都很类似,都有两个共同的词汇(推荐和系统)。而标题越短,两本书的相似程度越高,这也在情理之中,因为这样一来,不相同的词汇也就越少。鉴于完全没有共同词汇,第一本书与其他书籍中的两本完全没有类似的地方。
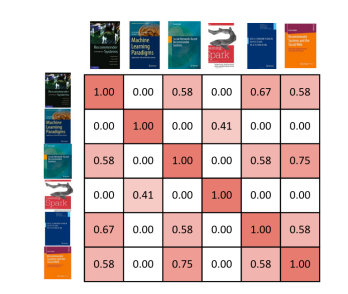
图四:第一本书与其他书籍间的相似性在单个维度中通过两本书之间的余弦相似度就能绘制出来。 我们还可以在相似矩阵中展示出所有书籍彼此间的相似程度(图五)。单元格的背景色表明了用户彼此间的相似程度,红色越深相似度越高。
图五:书籍间的相似矩阵,每个相似点都是基于书籍向量表示之间的余弦相似度。 现在我们知道每本书彼此间的相似程度了,可以为用户生成推荐结果。与基于物品的协同过滤方式类似,我们在之前的文章中也介绍过,推荐系统会根据用户之前评价过的书籍,来推荐其他书籍中相似度最高的。区别在于:相似度是基于书籍内容的,准确来说是标题,而不是根据使用数据。在本例中,系统会给第一个用户推荐第六本书,之后是第四本书(图六)。同样地,我们只取与用户之前评论过的书籍最相似的两本书。
图六:为某个用户生成推荐结果。我们取到他们之前评论过的书籍目录,找出与每本书籍最相似的两本,再对用户尚未评论过的书籍进行推荐。 4. 优缺点分析 ① 优点 (1)不需要惯用数据 (2)可以为具有特殊兴趣爱好的用户推荐罕见特性的项目 (3)可以使用用户内容特征提供推荐解释,信服度较高 (4)不需要巨大的用户群体或者评分记录,只有一个用户也可以产生推荐列表 (5)没有流行度偏见,能推荐新的或者不是很流行的项目,没有新项目问题 ② 缺点 (1)项目内容必须是机器可读和有意义的 (2)容易归档用户 (3)很难有意外,存在推荐结果新颖性问题,相似度太高,惊喜度不够 (4)很难联合多个项目的特性 (5)存在过度专业化问题 (6)浅层内容分析,对项目的分析不够全面 5. 补充 ① 最近邻方法(k-Nearest Neighbor,简称kNN) 对于一个新的item,最近邻方法首先找用户u已经评判过并与此新item最相似的k个item,然后依据用户u对这k个item的喜好程度来判断其对此新item的喜好程度。这种做法和CF中的item-based kNN很相似,差别在于这里的item相似度是根据item的属性向量计算得到,而CF中是根据所有用户对item的评分计算得到。 对于这个方法,比较关键的可能就是如何通过item的属性向量计算item之间的两两相似度。[2]中建议对于结构化数据,相似度计算使用欧几里得距离;而如果使用向量空间模型(VSM)来表示item的话,则相似度计算可以使用cosine。 ② Rocchio算法 Rocchio算法是信息检索中处理相关反馈(Relevance Feedback)的一个著名算法。比如你在搜索引擎里搜“苹果”,当你最开始搜这个词时,搜索引擎不知道你到底是要能吃的水果,还是要不能吃的苹果,所以它往往会尽量呈现给你各种结果。当你看到这些结果后,你会点一些你觉得相关的结果(这就是所谓的相关反馈了)。然后如果你翻页查看第二页的结果时,搜索引擎可以通过你刚才给的相关反馈,修改你的查询向量取值,重新计算网页得分,把跟你刚才点击的结果相似的结果排前面。比如你最开始搜索“苹果”时,对应的查询向量是 {“苹果” : 1}。而当你点击了一些与Mac、iPhone相关的结果后,搜索引擎会把你的查询向量修改为 {“苹果” : 1, “Mac” : 0.8, “iPhone” : 0.7},通过这个新的查询向量,搜索引擎就能比较明确地知道你要找的是不能吃的苹果了。Rocchio算法的作用就是用来修改你的查询向量的: {“苹果” : 1} --> {“苹果” : 1, “Mac” : 0.8, “iPhone” : 0.7}。在CB里,我们可以类似地使用Rocchio算法来获得用户u的profile
其中 在获得 Rocchio算法的一个好处是 正如在本节开头所说,本节要解决的是一个典型的有监督分类问题。所以各种有效的分类机器学习算法都可以用到这里。 ③ 决策树算法(Decision Tree,简称DT) 当item的属性较少而且是结构化属性时,决策树一般会是个好的选择。这种情况下决策树可以产生简单直观、容易让人理解的结果。而且我们可以把决策树的决策过程展示给用户u,告诉他为什么这些item会被推荐。但是如果item的属性较多,且都来源于非结构化数据(如item是文章),那么决策树的效果可能并不会很好。 ④ 线性分类算法(Linear Classifer,简称LC) 对于我们这里的二类问题,线性分类器(LC)尝试在高维空间找一个平面,使得这个平面尽量分开两类点。也就是说,一类点尽可能在平面的某一边,而另一类点尽可能在平面的另一边。 仍以学习用户u的分类模型为例。 其中的上角标t表示第t次迭代, 和Rocchio算法一样,上面更新公式的好处就是它可以以很小的代价进行实时更新,实时调整用户u对应的 说到这里,很多童鞋可能会想起一些著名的线性分类器:Logistic Regression和Linear SVM等等,它们当然能胜任我们这里的分类任务。[2]中提到Linear SVM用在文本分类上能获得相当不错的效果:)。 如果item属性 ⑤ 朴素贝叶斯算法(Naive Bayes,简称NB) NB算法就像它的简称一样,牛逼!NB经常被用来做文本分类,它假设在给定一篇文章的类别后,其中各个词出现的概率相互独立。它的假设虽然很不靠谱,但是它的结果往往惊人地好。再加上NB的代码实现比较简单,所以它往往是很多分类问题里最先被尝试的算法。我们现在的profile learning问题中包括两个类别:用户u喜欢的item,以及他不喜欢的item。在给定一个item的类别后,其各个属性的取值概率互相独立。我们可以利用用户u的历史喜好数据训练NB,之后再用训练好的NB对给定的item做分类。NB的介绍很多,这里就不再啰嗦了,有不清楚的童鞋可以参考NB Wiki,或者[1-3]。 转载请并标注: “本文转载自 linkedkeeper.com (文/肖依云)” ©著作权归作者所有 |


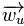
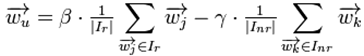
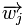 表示item j的属性,
表示item j的属性,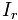 与
与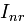 分别表示已知的用户u喜欢与不喜欢的item集合;而
分别表示已知的用户u喜欢与不喜欢的item集合;而 与
与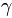 为正负反馈的权重,它们的值由系统给定。
为正负反馈的权重,它们的值由系统给定。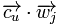 ,使得此平面尽量分开用户u喜欢与不喜欢的item。其中的
,使得此平面尽量分开用户u喜欢与不喜欢的item。其中的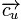 就是我们要学习的参数了。最常用的学习
就是我们要学习的参数了。最常用的学习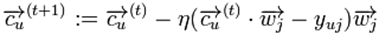
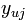 表示用户u对item j的打分(例如喜欢则值为1,不喜欢则值为-1)。
表示用户u对item j的打分(例如喜欢则值为1,不喜欢则值为-1)。 为学习率,它控制每步迭代变化多大,由系统给定。
为学习率,它控制每步迭代变化多大,由系统给定。
