

关于服务器性能的一些思考
系列文章:一、服务器性能 平常的工作中,在衡量服务器的性能时,经常会涉及到几个指标,load、cpu、mem、qps、rt,其中load、cpu、mem来衡量机器性能,qps、rt来衡量应用性能。 一般情况下对于机器性能,load、cpu、mem是越低越好,如果有一个超过了既定指标都代表着可能出现了问题,就需要尽快解决(当然有可能是应用的问题也有可能是机器上其他程序引起的),反正就是如果不解决,时间长了肯定不好。 而对于应用性能的两个指标,qps当然是希望越大越好,rt越小越好。提高qps可以充分利用机器资源,更少的机器来完成更多的请求,而降低rt会提升响应速度,提升用户体验。 平时做性能优化或者查找性能问题的目的,就是在提高qps,降低rt、保证load、cpu、mem稳定,但是至于他们之间有什么关系,是否有相互影响,各个指标主要由那些因素决定等等,往往是两眼一抹黑。优化点做了就是做了,至于会有什么结果,为什么会生效,会不会对其他指标有什么影响,心里多少是没有底的,先上线看看再说,不行再来。 本文的目的是梳理下日常工作中涉及到性能点时的一些思考,总结方法和理论,形成自己的方法论,希望对以后类似的工作有一定的指导。 文章的内容主要来自《服务器端性能优化-提升QPS、RT》、《由RT、QPS到问题排查思路》两篇PPT和ata上的一些文案的总结,涉及到具体测试案例可以参考着两篇ppt中的例子。 在文章开始前,大家可以思考几个具体的问题: 1. 如果要提高qps应该怎么做,如果要降低rt应该怎么做? 2. qps和rt的关系,降低rt就可以提高qps?qps低是因为rt高导致的? 3. 应用中线程的数量怎么设置,是越多越好,线程在应用性能中的作用是什么? 4. 系统负载和应用负荷的关系,系统负载高是由应用负荷引起的,如果不是还有什么原因? 二、应用性能 1、理论讨论 在进行理论总结之前,对接下来要用到的一些参数做下说明: qps:一秒钟内完成的请求数量 rt: 一个请求完成的时间 Tic: 线程的cpu计算时间 Tiw:线程的等待时间(io/网络/锁) Tn: 线程数 Tno:最佳线程数 Cn:cpu核数 Cu:cpu使用率 注:以下的讨论均限于机器负载小于平均负载的情况,机器负载太高的时候,以下的公式并不适用。 rt的计算公式:
qps计算:
对于rt和qps的计算公式大家都已经很熟悉,不做过多说明,在这里引出一个重要的概念,最佳线程数。 最佳线程数的定义:刚好消耗完服务器瓶颈资源的临界线程数。计算公式如下:
如何理解最佳线程数和其计算公式? 在一般的服务器上,程序运行的瓶颈资源有可能是cpu、也可以是内存、锁、IO等,他们都可以影响到程序运行的时间,体现在公式上就是Tic和Tiw,分表代表程序执行的cpu运行时间和程序等待资源的时间。因此理论上,为了让cpu充分使用,执行程序的线程数就是(Tic + Tiw)/Tic。 这里说下我对Tic和Tiw的理解,既然瓶颈资源不仅仅只是有cpu,为什么要把cpu单独拎出来,而其他种种都归结为Tiw。我想是因为机器的性能受影响的因素很多,不可能全部体现在公式中,为了方便计算和推理,所以选择了好统计的Tic做为一个主要指标,而其他都归结为Tiw。所以这只是一个计算上的技巧,公式不代表真实情况,但是公式可以给我们指明方向,简化思考的方法。 目前线上机器都是多核的,那么在多核情况下,应用qps的计算应该是:
Cu是cpu使用率,线上机器一般不会把cpu跑到100%,所以在计算qps时需要乘上一个系数,代表期望cpu使用率使用情况下的qps。 一般写代码的时候还会用到多线程,那么多核多线程下qps为:
多核最佳线程下qps:
可以看到在最佳线程下,qps的大小只和Tic成反比,也就是说要增大qps只要减小Tic就可以了。 但是最佳线程数的计算公式中可以看出,应用的最佳线程数是和实际的运行情况相关的,是一个随时变化的量,在应用运行过程中很难确定一个明确的值,所以qps的计算公式还需要根据实际情况来做下改变。最终qps计算如下,Tn一般是一个确定的值,即处理逻辑线程池的大小,而Tno是一个理论计算值。
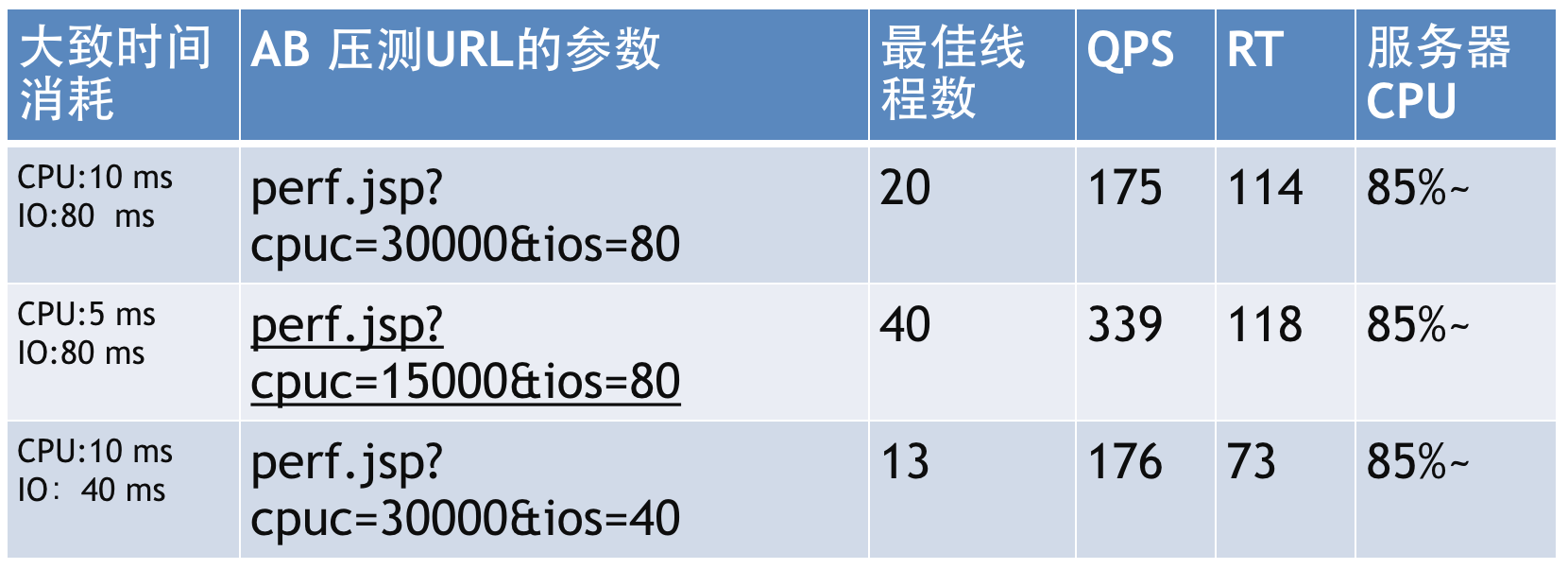
2、测试验证 现在让我们用例子在测试验证下。 注:这里的使用到的测试用例和数据来源于《服务器端性能优化-提升QPS、RT - 小邪》 压测模型如下:
对于我们大多数系统来说,业务逻辑都不是很复杂,需要耗费大量cpu计算的场景很少,因此Tic在rt中的占比不是很高,占比高的还是Tiw。 压测结果如下:
结论: 1. 要提高qps,最好的方法是降低Tic,优化cpu时间能达到更好的效果,比如:减少加密、解密、渲染、排序、查找、序列化等操作。 2. 要降低rt,则是降低Tiw,比如依赖的远程服务、数据库的读写、锁等,并且降低Tiw并不能带来qps的明显提升。 3、线程的大小 在之前的测试中,有一个既定条件,即线程的大小被预设为最佳线程数,但是线上机器运行过程中,最佳线程数是很难计算的,处理逻辑的线程池大小也不可能刚刚好就是最佳线程数,往往不是大了就是小了,只能接近于最佳线程数。 线程数过小的结果,qps上不去,cpu利用率不高,rt不变,这个很好理解,极端情况下只有一个线程,那么Tiw这段时间内,cpu其实是白白浪费了。 线程数过大(超过最佳线程数),我们先把结论摆出来,再来求证。 之前写到rt的计算方法是,rt=Tic+Tiw,但是这是单线程或者最佳线程情况下的,非最佳线程情况下,rt的计算公式应该如下:
即:rt = (并发线程数/最佳线程数)* 最佳线程时的rt。 我们对上面的公式进行下处理,可以得到:
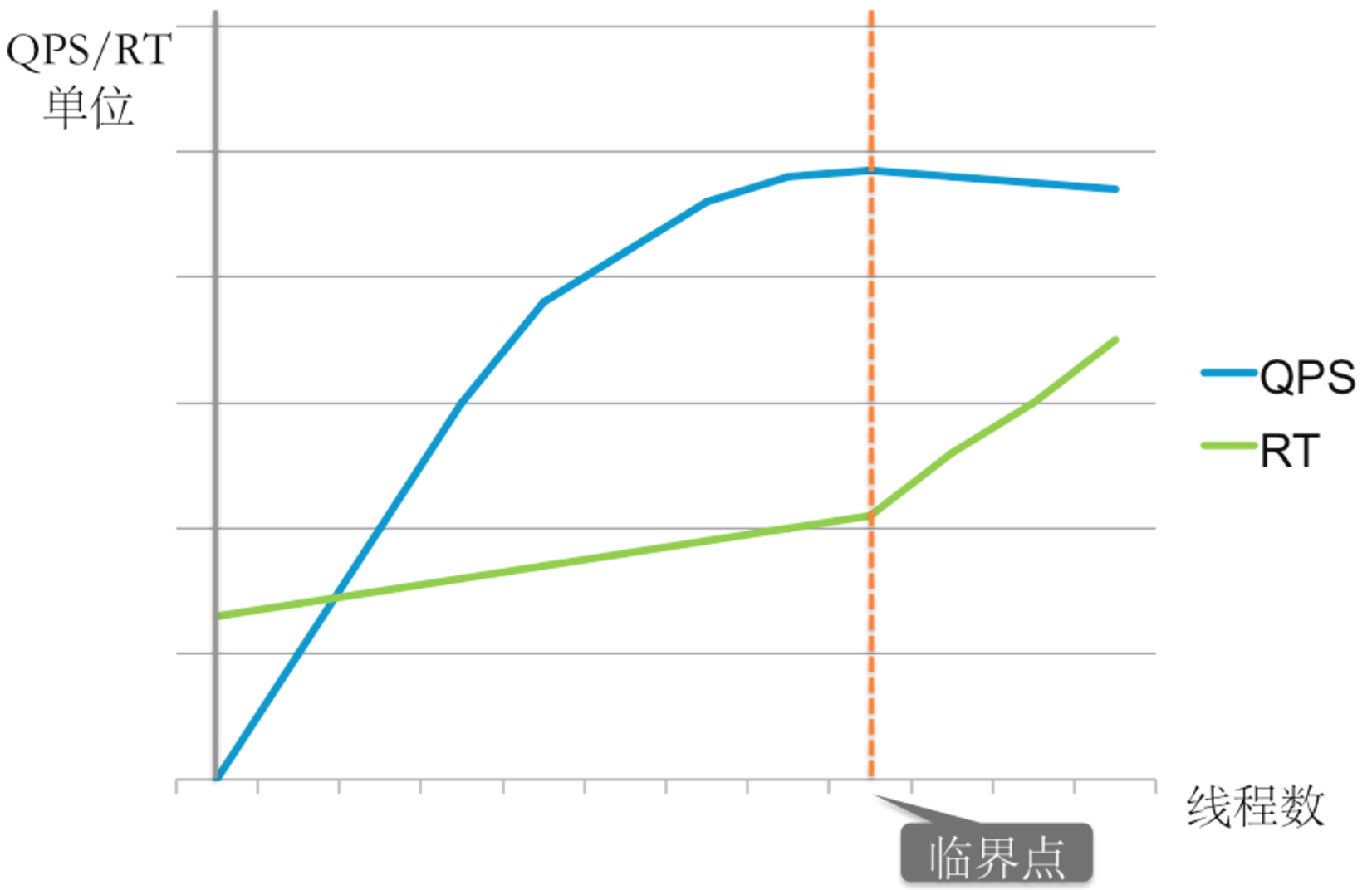
为什么呢,因为实际运行过程中,实际的最佳线程数的大小是不会超过设定的线程大小的,所以在Tn<Tno(Tno是理论计算值)的时候,实际的最佳线程数要小于理论值,等于线程数。 当线程的数量超过最佳线程数之后,rt的则和线程数正相关,即线程越多rt越长,这其实也是很好理解的,线程的rt由Tic和Tiw构成,一般情况下Tic不会有太大的变化,rt变成说明线程等待的时间变长,超过最佳线程之后,说明线程增加了一部分等待时间,有可能是在等待锁(锁的竞争更激烈)、或者是在等待cpu调度、或者是线程切换太高。 知道了线程数量对rt的影响,再回过头来看看线程数量对qps的影响。 在线程数没有达到最佳线程数之前,增加线程可以提高qps,同时rt不变(增加不大);当线程数超过了最近线程则qps不会在提高,而rt则会变大。 4、总结 一图来总结下线程数、qps、rt之间的关系:
在平时的应用性能优化过程中: 1. 首先要明确系统的瓶颈在哪里,是想提高qps还是降低rt,因为二者的思路是完全不同的。 2. 其次要逐步摸清应用性能的临界点,即最佳线程数,因为在达到最佳线程数之后,系统的表现会和之前完全不同,在超过最佳线程数之后,单靠提高线程数已经无法提升系统性能。 三、机器性能 接下来让我们来看看衡量机器性能的指标——load 和 cpu使用率。 cpu使用率:程序在运行期间实时使用的cpu比率。 load:代表着一段时间内正在使用和等待使用cpu的任务平均数,这是一个很玄妙的定义,我至今没有完全明白它的确切的定义和计算公式。 鉴于load的计算没有明确的计算公式,因此不好分析影响load的因素,也不好像应用性能那样总结出影响qps和rt的具体原因,现在只对load表现出来的问题做一些总结。 机器负荷高,但应用负荷不高 即机器的load很高,但是应用的qps、rt都不高,这种情况可能有以下几种原因: 1. 其他资源导致cpu利用率上不去,大量线程在执行其他动作或者在等待,比如io的速度太慢,内存gc等。 2. 如果系统资源不是瓶颈,则由可能是锁竞争、后端依赖的服务吞吐低、没有充分利用多核资源,多核却使用单线程。 查看机器load高的常见方法: 1. 机器的io(磁盘io、网络io):vmstat、iostat、sar -b等。 2. 网络io:iftop、iptraf、ntop、tcpdump等。 3. 内存:gc、swap、sar -r。 4. 锁竞争、上下文切换、后端依赖。 机器负荷高,应用负荷也高 即机器load很高,应用qps也很高: 1. 典型的cpu型应用,rt中Tiw很小,基本上全是cpu计算,可以尝试查找cpu耗的较多的线程,降低cpu计算的复杂度。 2. 应用的负荷真的很大,当所有优化手段都做了,还是无法降下来,可以考虑加机器,不丢人。 对于load偏高的原因,不仅仅只是有应用自身引起的,机器上其他程序也有可能导致机器整体的load偏高。 四、总结 影响系统性能的具体因素还有很多,如内存就是很常见的问题,内存泄露、频繁gc等,因此内存也应该被重视,限于篇幅,内存的问题不专门展开。 影响系统性能的因素有很多,没有一个明确的公式或者方法能说明是哪一个具体的因素对系统造成了多大的影响,对其他相关因素又产生了多大的影响,影响是好是坏。 正是因为这种复杂性和不确定性给系统性能优化和查找性能问题带来了困难,实际工作中还是要针对具体问题具体对待,但是我们可以对已知的问题和方法做归纳和总结,并逐步在实际问题中去验证和丰富扩充,以形成解决问题的方法论。 转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |
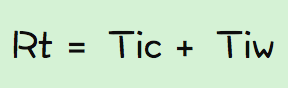
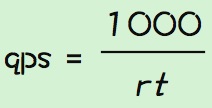
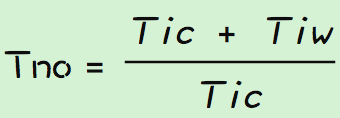
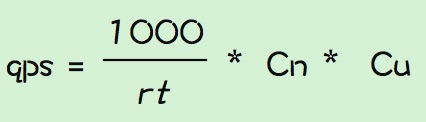
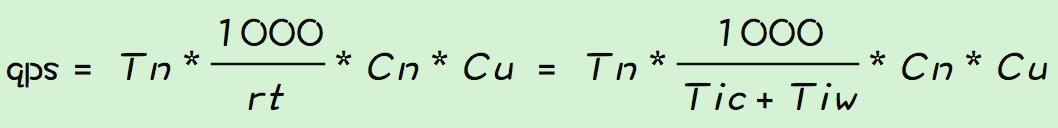
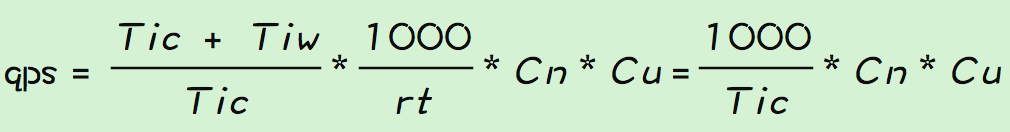
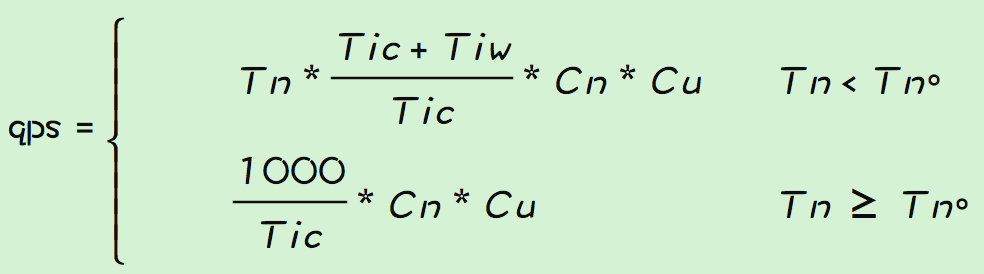

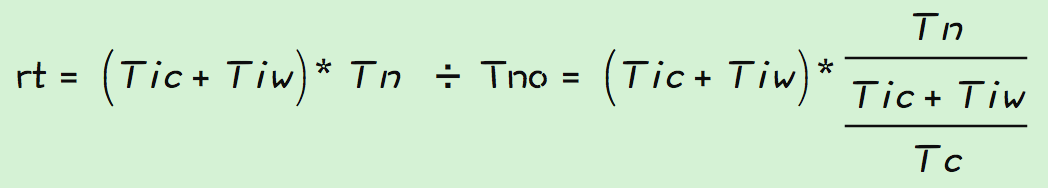


8546
阅读数


视频课程

好文推荐